데이터 조회
1. SELECT 문
1-1. 용도
SELECT 문은 일반적으로 테이플에 저장된 데이터를 가져오는 데 쓰인다.
SQL에서 가장 많이 쓰이는 문장이다.
1-2. SELECT 문법
1 | SELECT |
1-3. SELECT 문 실습
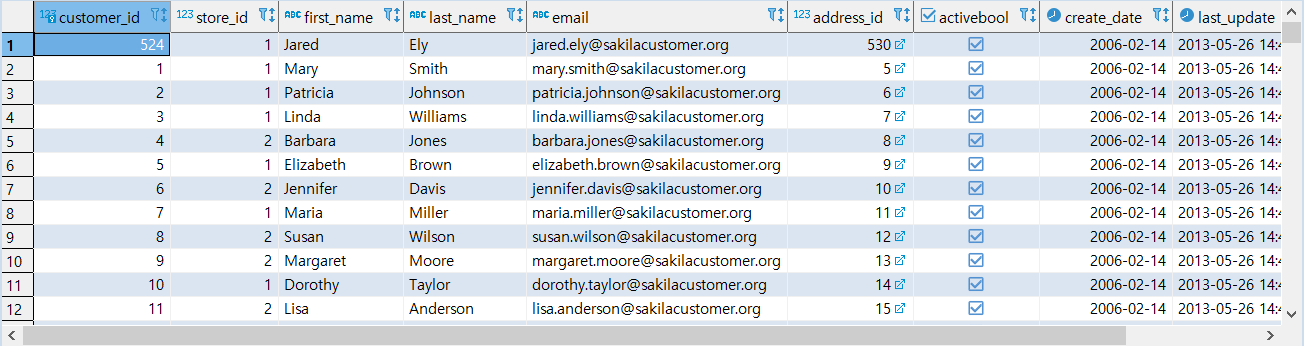
> 전체 컬럼을 조회
1 | SELECT |
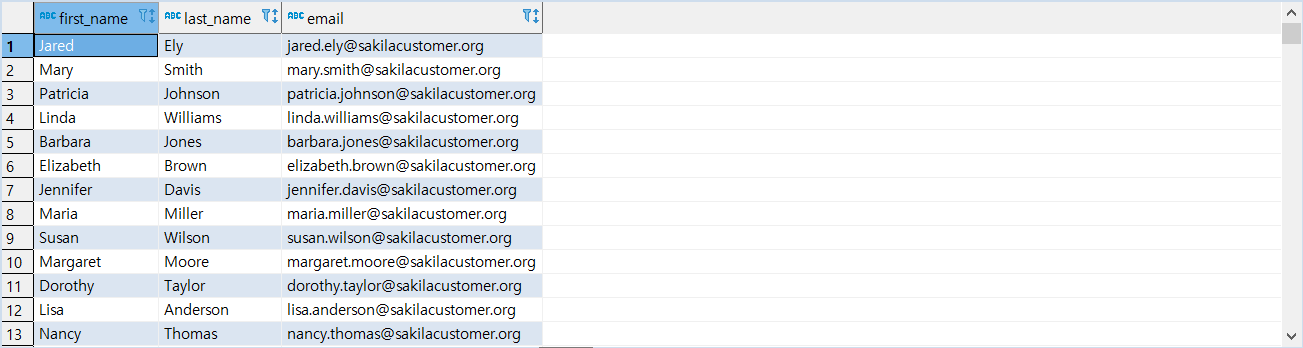
> 지정한 컬럼을 조회
1 | SELECT |
[주의] 여러 컬럼을 조회할 때, SELECT 명령어 뒤 컬럼 이름을 입력 시:
- 마지막 컬럼명을 제외한 모든 컬럼명 뒤에 따움표( , )를 붙여야 함
- 마지막 컬럼명 뒤에는 아무것도 입력하지 않는다
> 테이블 Alias(별칭) 활용하기
테이블에 별칭을 지정하면 코드의 가독성이 높아진다. 특히 테이블이 많아 지면, 선택한 컬럼이 어느 테이블에서 추출한 건지를 햇갈릴 수 있다. 테이블 별칭을 활용하면 보다 쉽게 구별할 수 있다.
1 | SELECT |
[주의] 테이블 Alias는 현재의 SELECT 문장에 대해서만 유효하다.
2. ORDER BY 문
2-1. 용도
ORDER BY 문은 SELECT 문에서 가져온 데이터를 정렬하는 데 사용한다.
업무 처리상 매우 중요한 기능이다.
2-2. ORDER BY 문법
ORDER BY를 활용하면 가져온 데이터를 특정 컬럼을 기준으로 오름차순(ASC) 혹은 내림차순(DESC)으로 정렬할 수 있다.
-
컬럼명 뒤에
ASC를 불이면 – 오름차순으로 정렬 -
컬럼명 뒤에
DESC를 불이면 – 내림차순으로 정렬 -
컬럼명 뒤에 아무것도 안 불이면 – Default로 오름차순으로 정렬
1 | SELECT |
2-3. ORDER BY 문 실습
1) 단일 기준 정렬
단일 컬럼을 기준으로 한 번의 정렬만 실시함.
> ASC(오름차순) 정렬
-
ORDER BY 미사용 시 (미정렬)
1
2
3
4
5SELECT
FIRST_NAME,
LAST_NAME
FROM
CUSTOMER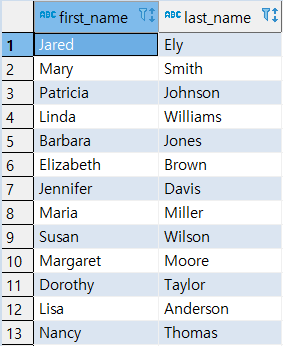
-
“FIRST_NAME” 기준으로 오름차순 정렬
1
2
3
4
5
6
7
8-- ASC 명령어 명시
SELECT
FIRST_NAME,
LAST_NAME
FROM
CUSTOMER
ORDER BY
FIRST_NAME ASC1
2
3
4
5
6
7
8-- Default로 정렬
SELECT
FIRST_NAME,
LAST_NAME
FROM
CUSTOMER
ORDER BY
FIRST_NAME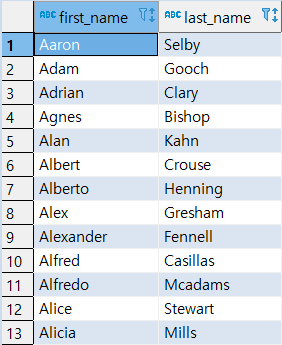
**> DESC(내림차순) 정렬 **
-
"FIRST_NAME"기준으로 내림차순 정렬
1
2
3
4
5
6
7SELECT
FIRST_NAME,
LAST_NAME
FROM
CUSTOMER
ORDER BY
FIRST_NAME DESC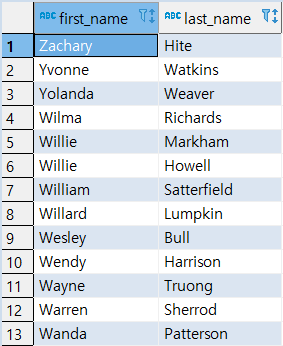
2) 다중 기준 N차 정렬
여러 컬럼을 기준으로 N차 정렬을 실시함.
-
COLUMN_1 기준으로 1차 정렬한 다음,
-
COLUMN_1의 값이 동일한 데이터에 대해서 COLUMN_2 기준으로 2차 정렬을 실시한다,
-
(위 규칙대로 계속 실행)…
> ASC(오름차순) + DESC(내림차순) 정렬
-
먼저 FIRST_NAME 오름차순으로 정렬, FIRST_NAME이 동일한 데이터는 LAST_NAME 내림차순으로 정렬
1
2
3
4
5
6
7
8SELECT
FIRST_NAME,
LAST_NAME
FROM
CUSTOMER
ORDER BY
FIRST_NAME DESC, -- 1차 정렬 (FIRST_NAME 내림차순)
LAST_NAME ASC -- 2차 정렬 (LAST_NAME 오름차순)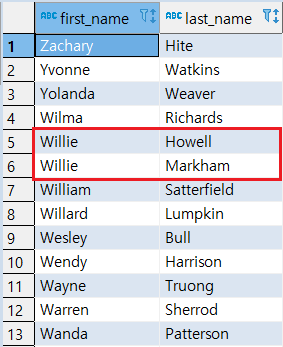
-
ORDER BY 기준을 정할 때, 컬럼명 내신에 SELECT 시 컬럼이 들어오는 순서로 대체해도 된다. (하지만 가독성을 위해 위 방법 더 추천)
1
2
3
4
5
6
7
8SELECT
FIRST_NAME,
LAST_NAME
FROM
CUSTOMER
ORDER BY
1 DESC, -- 1: FIRST_NAME (내림차순)
2 ASC -- 2: LAST_NAME (오름차순)
3. SELECT DISTINCT 문
3-1. 용도
SELECT 시 DISTINCT를 사용하면 중복 값을 제외한 결과값이 출력된다. 즉 같은 결과의 행이라면 중복을 제거할 수 있다.
3-2. SELECT DISTINCT 문법
1) 단일 컬럼
-
단일 컬럼을 추출할 때 해당 컬럼의 값이 중복된 행을 제거하여 추출
1
2
3
4-- COLUMN_1의 값이 중복 값 존재 시 중복 값을 제거
SELECT
DISTINCT COLUMN_1
FROM TABLE_NAME
2) 다중 컬럼
-
다중 컬럼을 추출할 때 모든 컬럼의 값이 모두 중복 된 행을 제거하여 추출
1
2
3
4
5-- COLUMN_1 + COLUMN_2의 값이 중복 값 존재 시 중복 값을 제거
SELECT
DISTINCT COLUMN_1, COLUMN_2
FROM
TABLE_NAME
>> 중복 값 제거 후 정렬하여 추출
1
2
3
4
5
6
7
8-- 결과를 명확하게 하기 위해 ORDER BY 절 사용
SELECT
DISTINCT COLUMN_1, COLUMN_2
FROM
TABLE_NAME
ORDER BY
COLUMN_1, -- default로 오름차순 정렬
COLUMN_2 -- default로 오름차순 정렬
-
다중 컬럼을 추출할 때 특정 컬럼의 값을 기준으로 중복된 행을 제거하여 추출 (DISTINCT ON 절)
[제거 규칙] 기준 컬럼의 값이 동일한 행 중에서 하나의 행만 보류
- 기본적으로 중복된 행 중의 첫 번째를 보류
- ORDER BY 문을 사용할 경우 정렬 후의 첫 번째 행을 보류
1
2
3
4
5SELECT
DISTINCT ON (COLUMN_1)
COLUMN_1, COLUMN_2
FROM
TABLE_NAME1
2
3
4
5
6
7
8SELECT
DISTINCT ON (COLUMN_1)
COLUMN_1, COLUMN_2
FROM
TABLE_NAME
ORDER BY
COLUMN_1
COLUMN_2
3-3. SELECT DISTINCT 문 실습
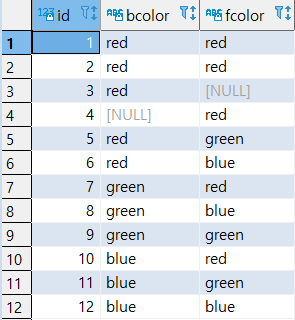
0) 실습 준비 (데이터 생성)
1 | CREATE TABLE T1 (ID SERIAL NOT NULL PRIMARY KEY, BCOLOR VARCHAR, FCOLOR VARCHAR); |
1 | SELECT |
1) 단일 컬럼
-
BCOLOR 컬럼의 값이 중복된 행을 제거 + BCOLOR 기준으로 정렬하여 추출
1
2
3
4
5
6SELECT
DISTINCT BCOLOR
FROM
T1
ORDER BY
BCOLOR

2) 다중 컬럼
-
BCOLOR & FCOLOR 두 컬럼을 추출 시:
-
두 컬럼 의 값이 모두 중복된 행을 제거
-
BCOLOR & FCOLOR 기준으로 정렬하여 추출
1
2
3
4
5
6
7
8SELECT
DISTINCT BCOLOR,
FCOLOR
FROM
T1
ORDER BY
BCOLOR,
FCOLOR -
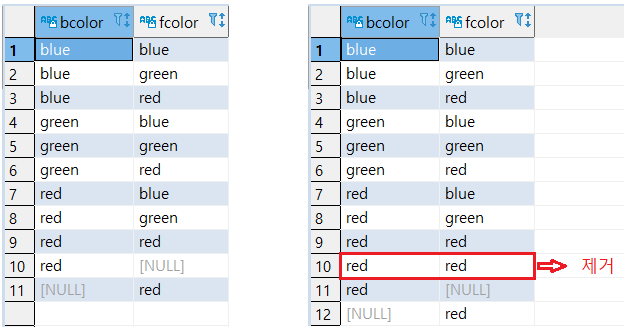
-
BCOLOR & FCOLOR 두 컬럼을 추출 시:
-
BCOLOR의 값을 기준으로 중복된 행을 제거
-
-
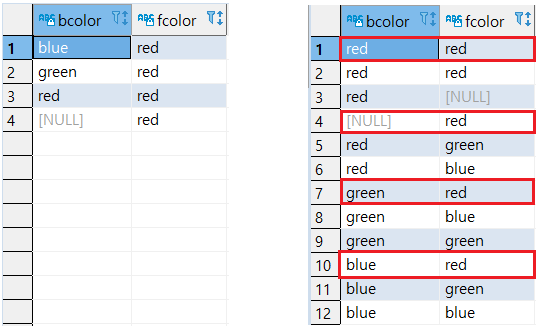
미정렬 시 BCOLOR값이 동일한 행 중에 첫 번째 행만 보류
-
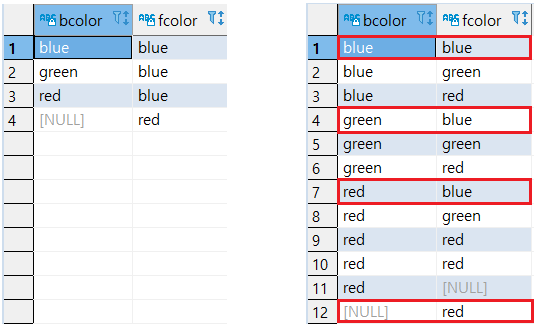
BCOLOR, FCOLOR 기준으로 정렬 시 FCOLOR의 첫 번째 값을 가진 행만 보류
-
1
2
3
4
5
6-- 미정렬 시
SELECT
DISTINCT ON (BCOLOR)
BCOLOR, FCOLOR
FROM
T1
1
2
3
4
5
6
7
8
9-- BCOLOR, FCOLOR 기준으로 정렬 (FCOLOR 오름차순)
SELECT
DISTINCT ON (BCOLOR)
BCOLOR, FCOLOR
FROM
T1
ORDER BY
BCOLOR,
FCOLOR
1
2
3
4
5
6
7
8
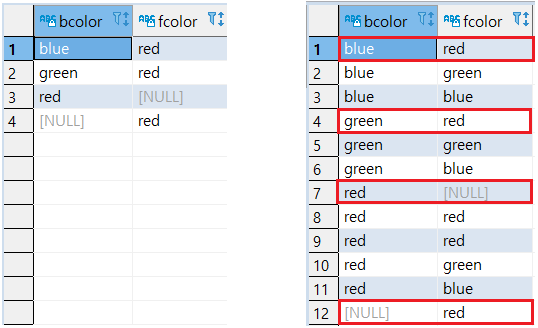
9-- BCOLOR, FCOLOR 기준으로 정렬 (FCOLOR 내림차순)
SELECT
DISTINCT ON (BCOLOR)
BCOLOR, FCOLOR
FROM
T1
ORDER BY
BCOLOR,
FCOLOR DESC
-
