집계 함수 (1) – 기초 집계 함수
1. GROUP BY 절
1-1. 개념
GROUP BY 절은 SELECT 문에서 반환된 행을 그룹으로 나눈다. 각 그룹에 대한 합계, 평균, 카운트 등을 계산할 수 있다.
1-2. GROUP BY 절 문법
1 | SELECT |
1-3. GROUP BY 절 실습
1-3-0. 실습 데이터
>> “dvdrental” 데이터 --> “payment” 테이블

1-3-1. 단순 GROUP BY
>> 특정 컬럼의 UNIQUE VALUE를 추출할 때 쓰이다 (SELECT DISTINCT과 유사)
[MISSION] 중복 값이 제거된 CUSTOMER_ID를 추출
1 | -- GROUP BY 사용 |
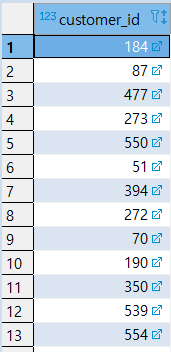
1 | -- [대체] SELECT DISTINCT 사용 |
1-3-2. GROUPING + GROUP 별 요약
1) 합계 구하기
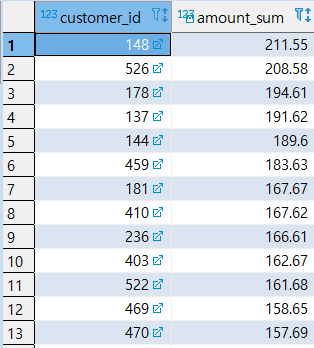
[MISSION] 거래액이 (AMOUNT의 합계) 가장 많은 고객순으로 출력
1 | -- 거래액이 (AMOUNT의 합계) 가장 많은 고객순으로 출력 |
2) 카운트 구하기
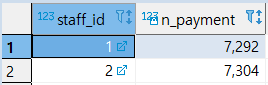
[MISSION 1] 직원별 처리한 결제 건수 출력
1 | -- 직원별 처리한 결제 건수 출력 |
[MISSION 2] STAFF 테이블에 있는 직원 이름 (FIRST_NAME, LAST_NAME)도 함께 추출
1 | -- STAFF 테이블에 있는 직원 이름 (FIRST_NAME, LAST_NAME)도 함께 추출 |

2. HAVING 절
2-1. 개념
HAVING 절은 GROUP BY 절과 함께 사용하여 GROUP BY의 결과를 특정 조건으로 필터링하는 기능을 한다.
2-2. HAVING 절 문법
1 | SELECT |
- HAVING 절은 GROUP BY 절에 의해 생성된 그룹행의 조건을 설정한다
- 반면에 WHERE 절은 GROUP BY 절이 적용된기 전에 개별 행의 조건을 설정한다
2-3. HAVING 절 실습
2-3-1. GROUP BY “합계” + HAVING
[GROUP BY 결과 출력]
1 | -- 거래액이 (AMOUNT의 합계) 가장 많은 고객순으로 출력 |
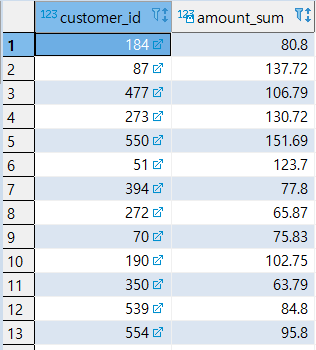
[MISSION 1] GROUP BY의 결과 값 중에서 AMOUNT_SUM이 200을 초과하는 행 출력
1 | -- AMOUNT_SUM > 200 |
- 주의: HAVING 절 뒤에 집계 데이터의 별칭(ALIAS)을 쓰면 안됨. (The HAVING clause is evaluated before the SELECT - so the server doesn’t yet know about that alias.)
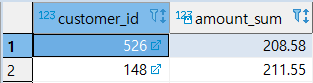
[MISSION 2] CUSTOMER 테이블에 있는 고객 이메일 주소 (EMAIL)도 함께 추출
1 | SELECT |

2-3-2. GROUP BY “카운트” + HAVING
[GROUP BY 결과 출력]
1 | -- 매장(STORE)별 구매 고객 수 추출 |
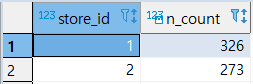
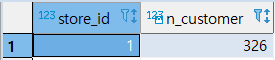
[MISSION] 구매 고객 수가 300 이상인 매장만 출력
1 | -- N_CUSTOMER > 300 |
1 | -- 해당 매장 정보 출력 |

