집합 연산자
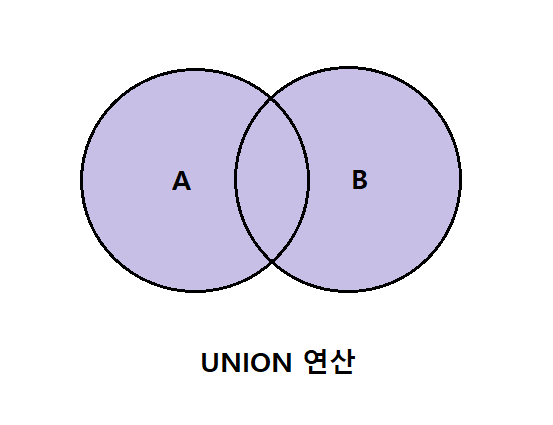
1. UNION 연산
1-1. 개념
두 개 이상의 SELECT 문들의 결과 집합을 단일 결과 집합으로 결합하며 결합 시 중복된 데이터는 제거 된다.
1-2. UNION 연산 문법
1
2
3
4
5
6
7
8
9
10
11
| SELECT
COLUMN_1_1,
COLUMN_1_2
FROM
TABLE_NAME_1
UNION
SELECT
COLUMN_2_1,
COLUMN_2_2
FROM
TABLE_NAME_2;
|
- 두 개의 SELECT 문 간 컬럼의 개수는 동일해야 하고 해당 순서의 열에는 서로 호환되는 데이터 유형이어야 한다.
- 두 개의 SELECT 문에서 중복되는 데이터 값이 있다면 중복을 제거 된다.
- ORDER BY 로 정렬하고자 할 경우 맨 마지막 SELECT문에 ORDER BY 절을 사용한다.
1-3. UNION 연산 실습
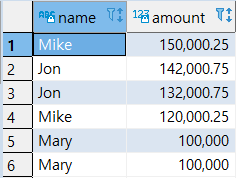
(1) 실습 준비
1
2
3
4
5
6
7
8
9
10
11
12
13
| CREATE TABLE SALES2007_1
(
NAME VARCHAR(50),
AMOUNT NUMERIC(15, 2)
);
INSERT INTO SALES2007_1
VALUES
('Mike', 150000.25),
('Jon', 132000.75),
('Mary', 100000);
COMMIT;
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| CREATE TABLE SALES2007_2
(
NAME VARCHAR(50),
AMOUNT NUMERIC(15, 2)
);
INSERT INTO SALES2007_2
VALUES
('Mike', 120000.25),
('Jon', 142000.75),
('Mary', 100000);
COMMIT;
|
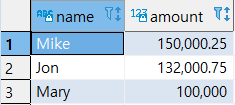
1
| SELECT * FROM SALES2007_1;
|
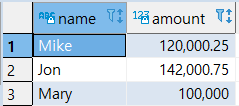
1
| SELECT * FROM SALES2007_2;
|
(2) UNION 연산 실습
>> 일반 UNION
1
2
3
4
5
6
7
8
9
10
|
SELECT
*
FROM
SALES2007_1
UNION
SELECT
*
FROM
SALES2007_2;
|
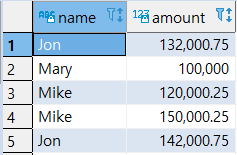
- (‘Mary’, ‘100000’) 중복 제거됨
1
2
3
4
5
6
7
8
9
10
|
SELECT
NAME
FROM
SALES2007_1
UNION
SELECT
NAME
FROM
SALES2007_2;
|
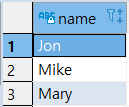
- ‘Mike’, ‘Jon’, ‘Mary’ 중복 제거됨
1
2
3
4
5
6
7
8
9
10
|
SELECT
AMOUNT
FROM
SALES2007_1
UNION
SELECT
AMOUNT
FROM
SALES2007_2;
|
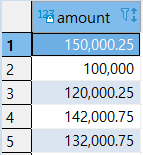
>> UNION + ORDER BY
1
2
3
4
5
6
7
8
9
10
11
| SELECT
*
FROM
SALES2007_1
UNION
SELECT
*
FROM
SALES2007_2
ORDER BY
AMOUNT DESC;
|
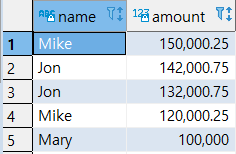
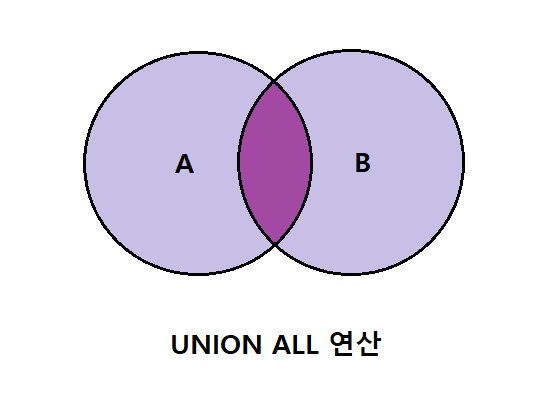
2. UNION ALL 연산
2-1. 개념
두 개 이상의 SELECT 문들의 결과 집합을 단일 결과 집합으로 결합하며 결합 시 중복된 데이터도 모두 출력한다.
2-2. UNION ALL 문법
1
2
3
4
5
6
7
8
9
10
11
| SELECT
COLUMN_1_1,
COLUMN_1_2
FROM
TABLE_NAME_1
UNION ALL
SELECT
COLUMN_2_1,
COLUMN_2_2
FROM
TABLE_NAME_2;
|
- 두 개의 SELECT 문 간 컬럼의 개수는 동일해야 하고 해당 순서의 열에는 서로 호환되는 데이터 유형이어야 한다.
- 두 개의 SELECT 문에서 중복되는 데이터 값이 있어도 모두 출력한다.
- ORDER BY 로 정렬하고자 할 경우 맨 마지막 SELECT문에 ORDER BY 절을 사용한다.
2-3. UNION ALL 실습
>> 일반 UNION ALL
1
2
3
4
5
6
7
8
9
10
|
SELECT
*
FROM
SALES2007_1
UNION ALL
SELECT
*
FROM
SALES2007_2;
|
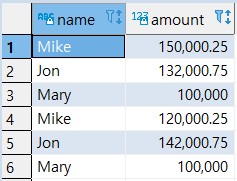
- (‘Mary’, ‘100000’) 중복 데이터 출력함
1
2
3
4
5
6
7
8
9
10
|
SELECT
NAME
FROM
SALES2007_1
UNION ALL
SELECT
NAME
FROM
SALES2007_2;
|
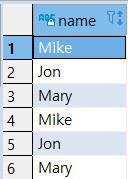
- ‘Mike’, ‘Jon’, ‘Mary’ 중복 데이터 출력함
1
2
3
4
5
6
7
8
9
10
|
SELECT
AMOUNT
FROM
SALES2007_1
UNION ALL
SELECT
AMOUNT
FROM
SALES2007_2;
|
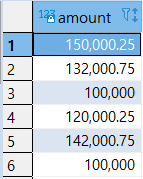
>> UNION ALL + ORDER BY
1
2
3
4
5
6
7
8
9
10
11
| SELECT
*
FROM
SALES2007_1
UNION ALL
SELECT
*
FROM
SALES2007_2
ORDER BY
AMOUNT DESC;
|
3. INTERSECT 연산
3-1. 개념
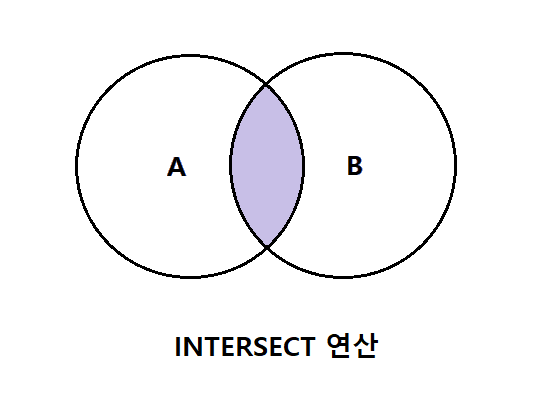
INTERSECT 연산자는 두 개 이상의 SELECT 문들의 결과 집합의 교집합을 출력하는 연산자다.
3-2. INTERSECT 연산 문법
1
2
3
4
5
6
7
8
9
10
11
| SELECT
COLUMN_1_1,
COLUMN_1_2
FROM
TABLE_NAME_1
INTERSECT
SELECT
COLUMN_2_1,
COLUMN_2_2
FROM
TABLE_NAME_2;
|
- 두 개의 SELECT 문 간 컬럼의 개수는 동일해야 하고 해당 순서의 열에는 서로 호환되는 데이터 유형이어야 한다.
- ORDER BY 로 정렬하고자 할 경우 맨 마지막 SELECT문에 ORDER BY 절을 사용한다.
3-3. INTERSECT 연산 실습
(1) 실습 준비
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| CREATE TABLE EMPLOYEES1
(
EMPLOYEE_ID SERIAL PRIMARY KEY,
EMPLOYEE_NAME VARCHAR(255) NOT NULL
);
CREATE TABLE KEYS
(
EMPLOYEE_ID INT PRIMARY KEY,
EFFECTIVE_DATE DATE NOT NULL,
FOREIGN KEY (EMPLOYEE_ID)
REFERENCES EMPLOYEES1 (EMPLOYEE_ID)
);
CREATE TABLE HIPOS
(
EMPLOYEE_ID INT PRIMARY KEY,
EFFECTIVE_DATE DATE NOT NULL,
FOREIGN KEY (EMPLOYEE_ID)
REFERENCES EMPLOYEES1 (EMPLOYEE_ID)
);
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| INSERT INTO EMPLOYEES1 (EMPLOYEE_NAME)
VALUES
('Joyce Edwards'),
('Diane Collins'),
('Alice Stewart'),
('Julie Sanchez'),
('Heather Morris'),
('Teresa Rogers'),
('Doris Reed'),
('Gloria Cook'),
('Evelyn Morgan'),
('Jean Bell');
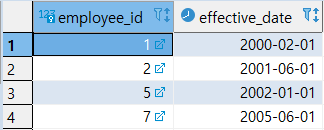
INSERT INTO KEYS
VALUES
(1, '2000-02-01'),
(2, '2001-06-01'),
(5, '2002-01-01'),
(7, '2005-06-01');
INSERT INTO HIPOS
VALUES
(9, '2000-01-01'),
(2, '2002-06-01'),
(5, '2006-06-01'),
(10, '2005-06-01');
|
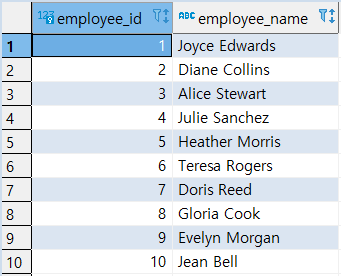
1
| SELECT * FROM EMPLOYEES1;
|
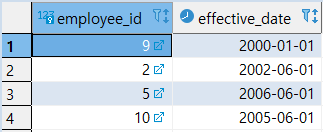
(2) INTERSECT 연산 실습
>> 일반 INTERSECT
1
2
3
4
5
6
7
8
9
10
|
SELECT
EMPLOYEE_ID
FROM
KEYS
INTERSECT
SELECT
EMPLOYEE_ID
FROM
HIPOS;
|
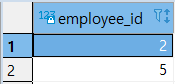
- INNER 조인 연산과 결과가 동일함** (실무에서 INTERSECT 연산 보다 INNER 조인 더 많이 쓰인다)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
SELECT
A.EMPLOYEE_ID
FROM
KEYS A
INNER JOIN
HIPOS B
ON A.EMPLOYEE_ID = B.EMPLOYEE_ID;
SELECT
A.EMPLOYEE_ID
FROM
KEYS A, HIPOS B
WHERE
A.EMPLOYEE_ID = B.EMPLOYEE_ID;
|
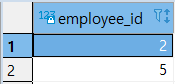
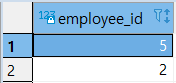
>> INTERSECT + ORDER BY
1
2
3
4
5
6
7
8
9
10
| SELECT
EMPLOYEE_ID
FROM
KEYS
INTERSECT
SELECT
EMPLOYEE_ID
FROM
HIPOS
ORDER BY EMPLOYEE_ID DESC;
|
4. EXCEPT 연산
4-1. 개념
EXCEPT 연산자는 맨위에 SELECT 문의 결과 집합에서 그 아래에 있는 SELECT 문의 결과 집합을 제외한 결과를 리턴한다. (실무에서 많이 쓰임)
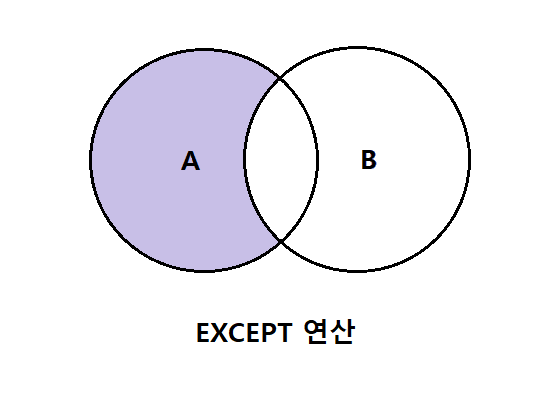
4-2. EXCEPT 연산 문법
1
2
3
4
5
6
7
8
9
10
| SELECT
COLUMN_1_1,
COLUMN_1_2
FROM
TABLE_NAME_1
SELECT
COLUMN_2_1,
COLUMN_2_2
FROM
TABLE_NAME_2;
|
- 두 개의 SELECT 문 간 컬럼의 개수는 동일해야 하고 해당 순서의 열에는 서로 호환되는 데이터 유형이어야 한다.
- ORDER BY 로 정렬하고자 할 경우 맨 마지막 SELECT문에 ORDER BY 절을 사용한다.
4-3. EXCEPT 연산 실습
>> 실습 데이터
dvdrental 데이터셋의 “film” 테이블(영화dvd 정보) 과 “inventory” 테이블(dvd 제고 정보) 을 활용한다.

- 한 편의 영화가 여러 개의 제고가 있을 수 있다
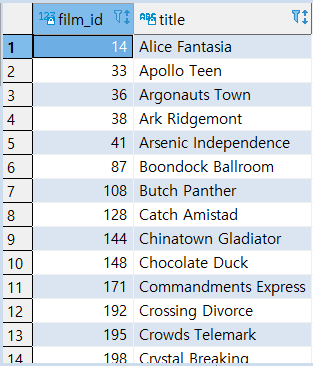
>> MISSION: 제고가 존재하지 않는 영화의 ID와 제목을 추출한다
(1) 먼저 제고가 존재하는 영화의 ID와 제목을 추출
1
2
3
4
5
6
7
8
9
| SELECT DISTINCT
A.FILM_ID,
B.TITLE
FROM
INVENTORY A
INNER JOIN
FILM B
ON A.FILM_ID = B.FILM_ID
ORDER BY B.TITLE;
|
(2) 이제 전체 영화에서 제고 있는 영화를 제거하면 제거 없는 영화의 정보를 추출할 수 있다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| SELECT
FILM_ID,
TITLE
FROM
FILM
EXCEPT
SELECT DISTINCT
A.FILM_ID,
B.TITLE
FROM
INVENTORY A
INNER JOIN
FILM B
ON A.FILM_ID = B.FILM_ID
ORDER BY TITLE;
|