서브쿼리
1. 서브쿼리란?
1-1. 개념
서브쿼리는 SQL문 내에서 메인 쿼리가 아닌 하위에 존재하는 쿼리를 말한다.
서브쿼리를 활용함으로써 다양한 결과를 도출할 수 있다.
1-2. 서브쿼리 이해
[MISSION]
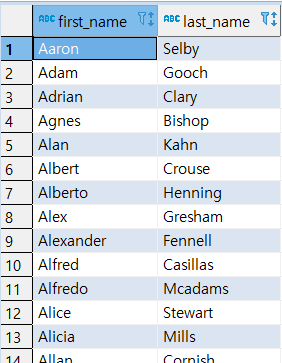
FILM 테이블에서 RENTAL_RATE가 평균 보다 큰 집합 구하기
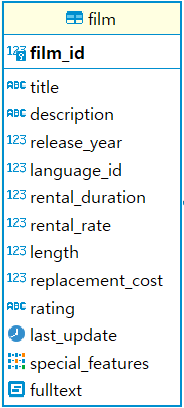
>> Method 1: 메인쿼리 2개 사용
1 | SELECT |
1 | SELECT |
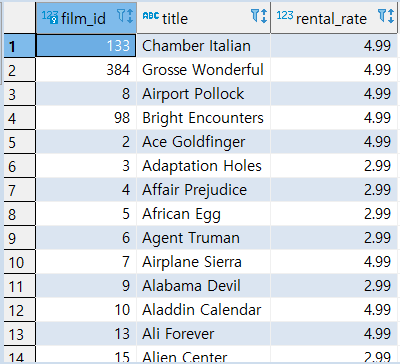
Q: 위 2개의 SQL문을 결합하여 하나의 SQL문으로 결과를 도출할 수 없을까?
A: 서브쿼리를 사용하면 된다! (중첩 서브쿼리, 인라인 뷰, 스칼라 서브쿼리가 존재한다.)
>> Method 2: 서브쿼리 사용
(1) 중첩 서브쿼리의 활용
중첩 서브쿼리 (Nested Subquery): 메인쿼리의 WHERE절에 나타나는 서브쿼리
1 | SELECT |
(2) 인라인 뷰의 활용
인라인 뷰 (Inline View): 메인쿼리의 FROM 절에 나타나는 서브쿼리 (서브쿼리 SELECT 절의 결과를 메인쿼리의 FROM 절에서 하나의 테이블처럼 사용)
1 | SELECT |
(3) 스칼라 서브쿼리의 활용
스칼라 서브쿼리 (Scala Subquery): SELECT의 리스트 안에 존재하는 서브쿼리
1 | SELECT |
2. ANY 연산자
2-1. 개념
ANY 연산자는 주로 메인쿼리 WHERE절의 비교 조건식에서 서브쿼리와 함께 사용된다. 서브쿼리에 의해 반환된 값 집합과 비교할 때 한번이라도 조건에 만족한다면 TURE를 반환한다. (즉, 서브쿼리 결과 집합중의 어떤 한 값 보다만 어떻다라면 TRUE를 반환)
2-2. ANY 연산자 실습
>> 준비
먼저 영화 분류별 상영시간이 가장 긴 영화의 카테고리 ID 및 상영시간을 출력
1 | SELECT |
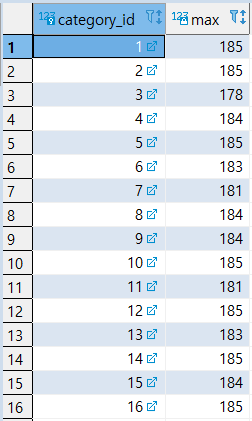
>> MISSION 1
영화의 상영시간이 위 집합 중 어느 하나의(ANY) 값 보다만 크거나 같으면 추출 [즉, 위에서 추출된 값 들의 최소값 보다만 크거나 같으면 추출]
" >= ANY " 활용
1 | SELECT |
-
서브쿼리가 반환되는 결과가 하나의 값이 아닌 여러 값의 집합이기 때문에 ANY 연산자를 안 쓰면 ERROR가 난다. (명확한 기준이 없기 때문)
1
2
3
4
5
6
7
8
9
10
11
12
13SELECT
TITLE, LENGTH
FROM
FILM
WHERE
LENGTH >=
(
SELECT MAX(LENGTH)
FROM FILM A,
FILM_CATEGORY B
WHERE A.FILM_ID = B.FILM_ID
GROUP BY B.CATEGORY_ID
);
>> MISSION 2
영화의 상영시간이 위에서 추출된 값들과 동일한 영화만 추출 [즉, 위 집합 중 어느 하나의(ANY) 값과 같으면 추출]
" = ANY " 활용
1 | SELECT |
-
"=ANY"는 "IN"과 동일
의미: 추출된 결과 집합 리스트 안의 값들과 매칭되는 값들을 찾는다
1
2
3
4
5
6
7
8
9
10
11
12
13SELECT
TITLE, LENGTH
FROM
FILM
WHERE
LENGTH IN
(
SELECT MAX(LENGTH)
FROM FILM A,
FILM_CATEGORY B
WHERE A.FILM_ID = B.FILM_ID
GROUP BY B.CATEGORY_ID
);
3. ALL 연산자
3-1. 개념
ALL 연산자는 주로 메인쿼리 WHERE절의 비교 조건식에서 서브쿼리와 함께 사용된다. 서브쿼리에 의해 반환된 값 집합과 비교할 때 모두 조건에 만족해야만 TURE를 반환한다. (즉, 서브쿼리 결과 집합중의 모든 값 보다 어떻다해야 TRUE를 반환)
3-2. ALL 연산자 실습
>> MISSION 1
[준비] : 먼저 영화 분류별 상영시간이 가장 긴 영화의 카테고리 ID 및 상영시간을 출력
1 | SELECT |
[MISSION] : 영화의 상영시간이 위 집합의 모든(ALL) 값 보다 크거나 같아야 추출 [즉, 위에서 추출된 값 들의 최대값 보다 크거나 같아야 추출]
1 | SELECT |
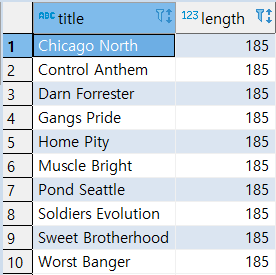
>> MISSION 2
[준비] : 먼저 평가기준(RATING)별 영화의 평균 상영시간을 출력
1 | SELECT |
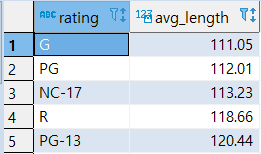
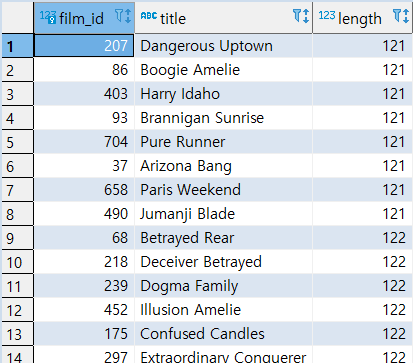
[MISSION] : 위에서 출력된 평균 상영시간보다 긴 영화의 정보를 출력
1 | SELECT |
4. EXISTS 연산자
4-1. 개념
EXISTS 연산자는 주로 메인쿼리 WHERE절에서 서브쿼리와 함께 사용된다.
동작원리는 다음과 같습니다:
-
먼저 메인쿼리의 TABLE에 접근하여 하나의 레코드를 가져온다.
-
이 레코드에 대해서 EXISTS 이하의 서브쿼리를 실행하고 서브쿼리에 의해 반환된 값 집합이 존재하는지를 판단한다.
-
서브쿼리에 의해 반환된 값 집합이 존재한다면
TRUE를 반환하고 메인쿼리의 SELECT문을 그대로 실행한다.반환된 값 집합이 존재하지 않다면
FALSE를 반환하고 메인쿼리의 SELECT문을 실행하지 않고 바로 다음 레코드로 넘어간다.
>> 장점: 서브쿼리에 의해 반환된 값 집합의 존재여부만을 판단하므로 연산 시 부하가 줄어든다 (성능상 유리함)
EXISTS 연산자와 IN 연산자의 차이점은 Tigercow.Dor님의 IN / EXISTS / NOT IN / NOT EXISTS 비교 에서 자세히 설명되어 있음. 참고 바람.
4-2. EXISTS 연산자 실습
>> MISSION
지불내역(AMOUNT)이 11달러 초과한 고객의 이름을 출력하라
1 | SELECT |
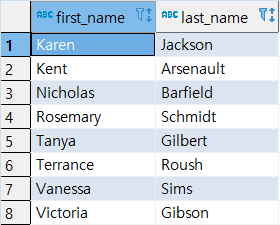
-
동작 순서:
-
먼저 메인쿼리의 CUSTOMER 테이블에서 N번째 레코드를 가져온다
-
그 다음 EXISTS 이하의 서브쿼리를 실행:
PAYMENT 테이블에서
- CUSTOMER_ID는 CUSTOMER 테이블의 CUSTOMER_ID과 동일하면서 (가져온 N번째 레코드의 CUSTOMER_ID랑만 비교)
- 지불내역(AMOUNT)이 11달러 초과한
값의 존재 여부를 판단(하여 TURE이면 1를 반환)
-
STEP 2에서
-
TURE로 판단되면 메인쿼리의 SELECT문을 그대로 실행 (즉 N번째 고객의 이름을 추출);
-
FALSE로 판단되면 메인쿼리의 SELECT 문을 실현하지 않고 그 다음 레코드 (N+1 번째 레코드)를 가져와 STEP 2 를 진행한다.
-
-
위 과정을 반복하여 마지막 레코드까지 완료되면 해당 SQL문의 동작이 종료된다.
-
5. NOT EXISTS 연산자
5-1. 개념
NOT EXISTS 연산자는 주로 메인쿼리 WHERE절에서 서브쿼리와 함께 사용된다. 위에서 EXISTS에 대해서 이해했다면 크게 어려운 점이 없다.
동작원리는 다음과 같습니다:
-
먼저 메인쿼리의 TABLE에 접근하여 하나의 레코드를 가져온다.
-
이 레코드에 대해서 EXISTS 이하의 서브쿼리를 실행하고 서브쿼리에 의해 반환된 값 집합이 존재하는지를 판단한다.
-
STEP 3는 EXISTS 연산자와 정 반대이다:
서브쿼리에 의해 반환된 값 집합이 존재하지 않다면
TRUE를 반환하고 메인쿼리의 SELECT문을 그대로 실행한다.반환된 값 집합이 존재한다면
FALSE를 반환하고 메인쿼리의 SELECT문을 실행하지 않고 바로 다음 레코드로 넘어간다.
>> 장점: 서브쿼리에 의해 반환된 값 집합의 존재여부만을 판단하므로 연산 시 부하가 줄어든다 (성능상 유리함)
5-2. NOT EXISTS 연산자 실습
>> MISSION
지불내역(AMOUNT)이 11달러 초과한 적이 없는 고객의 이름을 출력하라
1 | SELECT |