[1] 아래 SQL문은 FILM 테이블을 2번 스캔하고 RENTAL_RATE가 평균 이상인 FILM의 ID, 제목과 RENTAL_RATE를 출력했다. FILM 테이블을 한번만 SCAN하여 동일한 결과 집합을 구하는 SQL을 작성하라.
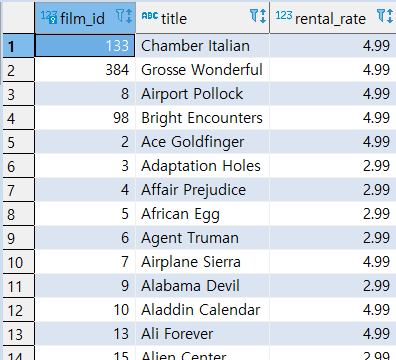
>> 두 번 스캔
1 2 3 4 5 6 7 8 9 10 11 12 13
SELECT FILM_ID, TITLE, RENTAL_RATE FROM FILM WHERE RENTAL_RATE > ( SELECT AVG(RENTAL_RATE) FROM FILM );
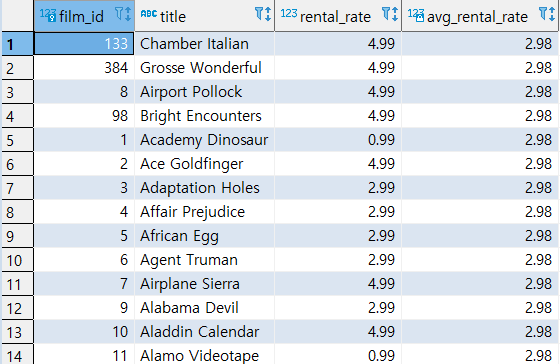
>> 한 번만 스캔
1) 우선 분석함수 AVG를 사용해서 평균을 구한다.
1 2 3 4 5 6 7
SELECT FILM_ID, TITLE, RENTAL_RATE, AVG(RENTAL_RATE) OVER() AS AVG_RENTAL_RATE FROM FILM
2) 1번에서 구한 집합을 인라인뷰로 감싸서 평균보다 큰 값을 구한다.
1 2 3 4 5 6 7 8 9 10 11 12 13
SELECT FILM_ID, TITLE, RENTAL_RATE FROM ( SELECT FILM_ID, TITLE, RENTAL_RATE, AVG(RENTAL_RATE) OVER() AS AVG_RENTAL_RATE FROM FILM ) A WHERE A.RENTAL_RATE > A.AVG_RENTAL_RATE;
똑같은 결과가 나오는 것을 확인할 수 있다
[2] 아래 SQL문은 EXCEPT 연산을 사용하여 재고가 없는 영화를 구하고 있다. 해당 SQL문은 EXCEPT연산을 사용하지 말고 같은 결과를 도출하라.
>> EXCEPT 연산 사용
1 2 3 4 5 6 7 8 9 10 11 12 13
SELECT FILM_ID, TITLE FROM FILM EXCEPT SELECTDISTINCT INVENTORY.FILM_ID, TITLE FROM INVENTORY INNERJOIN FILM ON FILM.FILM_ID = INVENTORY.FILM_ID ORDERBY TITLE;
>> NOT EXISTS 연산 사용
1 2 3 4 5 6 7 8 9 10 11 12
SELECT FILM_ID, TITLE FROM FILM F WHERE NOTEXISTS ( SELECT * FROM INVENTORY I WHERE F.FILM_ID = I.FILM_ID );