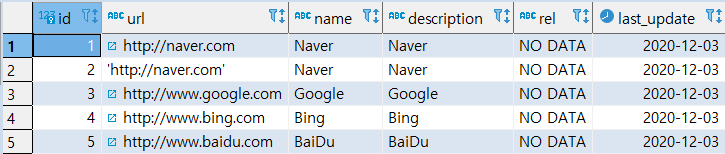
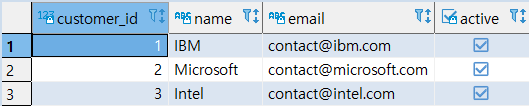
INSERTINTO CUSTOMERS (NAME, EMAIL) VALUES ('Microsoft', 'hotline@microsoft.com') ON CONFLICT (NAME) -- 충돌 시(기존에 존재할 경우) DONOTHING; -- 아무 것도 안함
COMMIT;
해당 DO NOTHING 명령어 없으면 SQL ERROR 발생
1 2 3 4
INSERTINTO CUSTOMERS (NAME, EMAIL) VALUES ('Microsoft', 'hotline@microsoft.com') ON CONFLICT (NAME)
>> UPSERT 문 실습 – UPDATE
UPDATE: INSERT 액션이 충돌 시 (기존에 존재할 경우) UPDATE 함
[MISSION] Microsoft(기존에 존재하는 NAME)에 EMAIL 주소 추가
'Microsoft’라는 NAME이 이미 존재하므로 NAME의 UNIQUE 조건과 충돌
이런 경우에 데이터를 UPDATE함
1 2 3 4 5 6 7 8 9
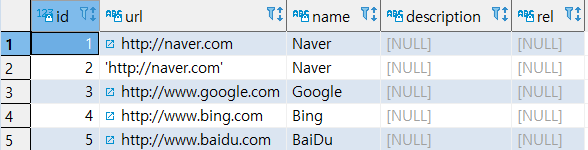
INSERTINTO CUSTOMERS (NAME, EMAIL) VALUES ('Microsoft', 'hotline@microsoft.com') ON CONFLICT (NAME) -- 충돌 검증 컬럼 DOUPDATE SET EMAIL = EXCLUDED.EMAIL || '; ' || CUSTOMERS.EMAIL; -- EXCLUDED.EMAIL은 위에서 INSERT 시도한 EMAIL값을 가리킴 COMMIT;
3. EXPORT 작업
3-1. 개념
EXPORT는 테이블의 데이터를 다른 형태의 데이터로 추출하는 작업이다. 대표적으로 CSV 형식으로 가장 많이 추출한다.
3-2. EXPORT 작업 실습
1
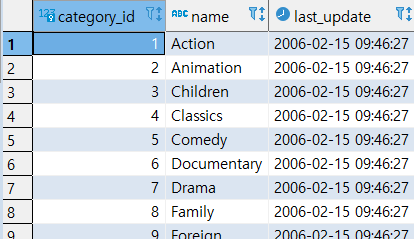
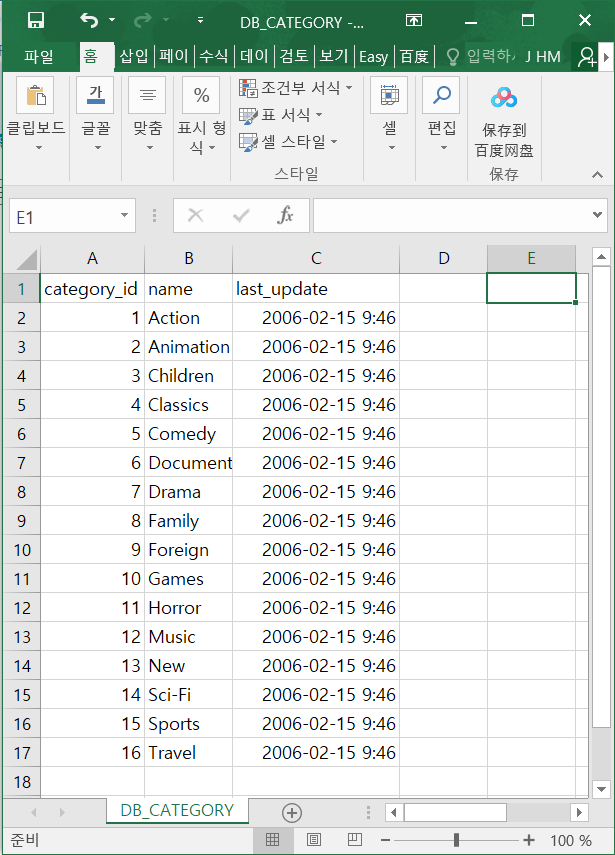
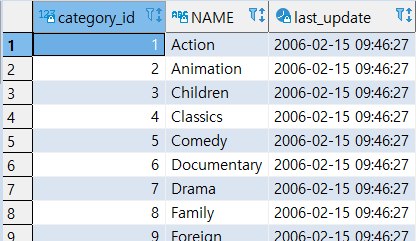
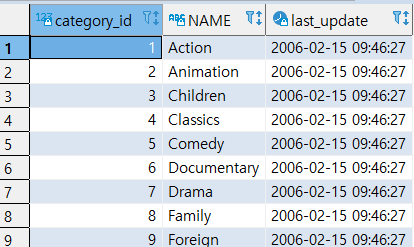
SELECT * FROM DATEGORY;
>> 실습 – 엑셀(.CSV) 형식으로 출력
1 2 3 4
COPY CATEGORY (CATEGORY_ID, NAME, LAST_UPDATE) -- 추출할 테이블과 컬럼을 지정 TO 'E:\Study_SQL\DB_CATEGORY.csv' -- 추출한 데이터를 저장할 파일을 지정 DELIMITER ',' -- 구분자를 지정 CSV HEADER; -- 파일 형식을 지정
저장 디랙토리(폴더)는 반드시 미리 존재해야 한다 (여기서는 ‘E:\Study_SQL’)
>> 실습 – 텍스트(.TXT) 파일로 출력
1 2 3 4
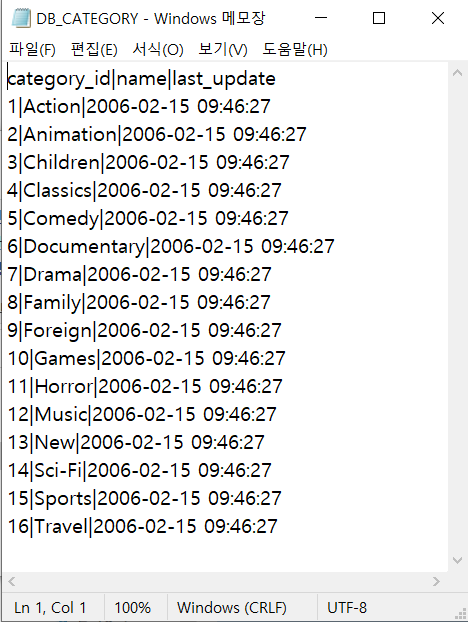
COPY CATEGORY(CATEGORY_ID, NAME, LAST_UPDATE) TO 'E:\Study_SQL\DB_CATEGORY.txt' DELIMITER '|' CSV HEADER;
>> 실습 – 컬럼명 없이 출력
1 2 3 4
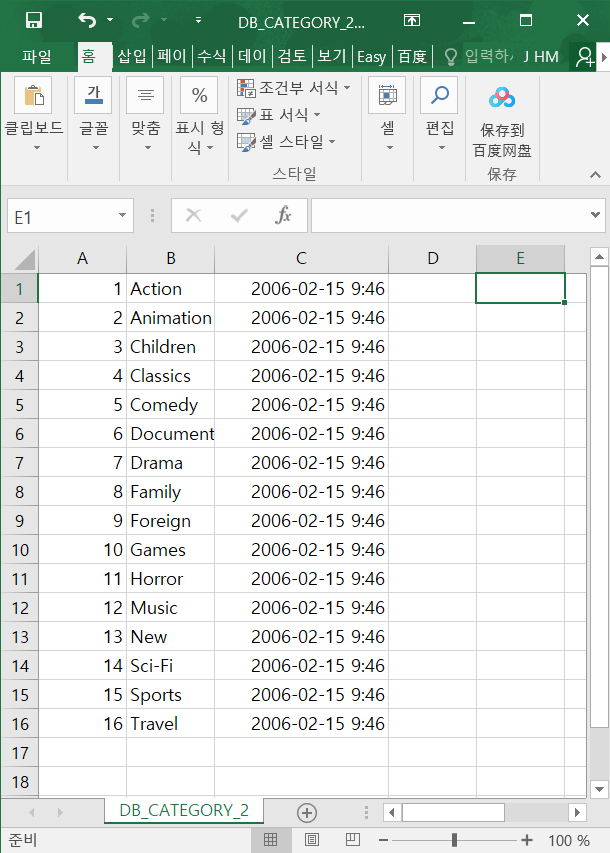
COPY CATEGORY(CATEGORY_ID, NAME, LAST_UPDATE) TO 'E:\Study_SQL\DB_CATEGORY_2.csv' DELIMITER ',' CSV;
4. IMPORT 작업
4-1. 개념
IMPORT는 다른 형식의 데이터를 테이블에 넣는 작업을 말한다. 데이터 구축 시 자주 사용 된다.
COPY CATEGORY_IMPORT(CATEGORY_ID, "NAME", LAST_UPDATE) -- 적재할 테이블 및 컬럼을 지정 FROM 'E:\Study_SQL\DB_CATEGORY.csv' -- 적재할 파일을 지정 DELIMITER ',' -- 적재할 파일의 구분자를 알려준다 CSV HEADER; -- 파일 형식을 지정한다
1
SELECT * FROM CATEGORY_IMPORT;
>> 실습 – 텍스트 파일을 적재
1 2 3
-- 실습 전 먼저 데이터를 삭제해야 함 DELETEFROM CATEGORY_IMPORT; COMMIT;
1 2 3 4
COPY CATEGORY_IMPORT(CATEGORY_ID, "NAME", LAST_UPDATE) FROM 'E:\Study_SQL\DB_CATEGORY.txt' DELIMITER '|' CSV HEADER;
1
SELECT * FROM CATEGORY_IMPORT;
>> 실습 – 컬럼명이 없는 엑셀 파일 적재
1 2 3
-- 실습 전 먼저 데이터를 삭제해야 함 DELETEFROM CATEGORY_IMPORT; COMMIT;
1 2 3 4 5 6
COPY CATEGORY_IMPORT(CATEGORY_ID, "NAME", LAST_UPDATE) FROM 'E:\Study_SQL\DB_CATEGORY_2.csv' DELIMITER ',' CSV;
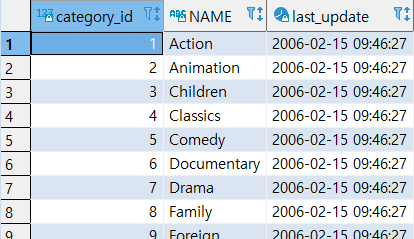
SELECT * FROM CATEGORY_IMPORT;
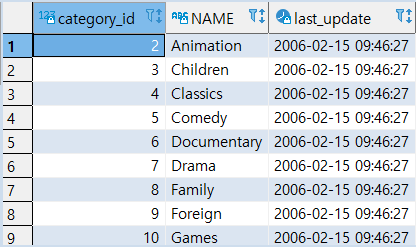
DB_CATEGOROY_2.csv 파일은 컬럼명(header) 이 존재하지 않으므로 반드시 HEADER를 제거해야한다.
HEADER를 제거하지 않을 경우 가장 첫번째 데이터를 헤더로 인식하여 한건이 누락된다
1 2
DELETEFROM CATEGORY_IMPORT; COMMIT;
1 2 3 4 5 6
COPY CATEGORY_IMPORT(CATEGORY_ID, "NAME", LAST_UPDATE) FROM 'E:\Study_SQL\DB_CATEGORY_2.csv' DELIMITER ',' CSV HEADER;