통계 기반의 시각화
- 0. 통계 기반의 시각화를 제공해주는 Seaborn
- 1. countplot
- 2. distplot
- 3. heatmap
- 4. pairplot
- 5. violinplot
- 6. lmplot
- 7. relplot
- 8. jointplot
1 | import numpy as np |
1 | plt.rcParams["figure.figsize"] = (9, 6) # figure size 설정 |
0. 통계 기반의 시각화를 제공해주는 Seaborn
reference: Seaborn 공식 도큐먼트
seaborn 라이브러리가 매력적인 이유는 바로 통계 차트다.
이번 실습에서는 seaborn의 다양한 통계 차트 중 대표적인 차트 몇 개를 뽑아서 다뤄볼 예정이다.
그럼 먼저 실습에 사용되는 Dataset을 한번 살펴볼게요.
Dataset — "Titanic"
1 | titanic = sns.load_dataset('titanic') |
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 0 | 2 | male | 27.0 | 0 | 0 | 13.0000 | S | Second | man | True | NaN | Southampton | no | True |
| 887 | 1 | 1 | female | 19.0 | 0 | 0 | 30.0000 | S | First | woman | False | B | Southampton | yes | True |
| 888 | 0 | 3 | female | NaN | 1 | 2 | 23.4500 | S | Third | woman | False | NaN | Southampton | no | False |
| 889 | 1 | 1 | male | 26.0 | 0 | 0 | 30.0000 | C | First | man | True | C | Cherbourg | yes | True |
| 890 | 0 | 3 | male | 32.0 | 0 | 0 | 7.7500 | Q | Third | man | True | NaN | Queenstown | no | True |
891 rows × 15 columns
-
survived: 생존여부
-
pclass: 좌석등급 (숫자)
-
sex: 성별
-
age: 나이
-
sibsp: 형제자매 + 배우자 숫자
-
parch: 부모 + 자식 숫자
-
fare: 요금
-
embarked: 탑승 항구
-
class: 좌석등급 (영문)
-
who: 사람 구분
-
deck: 데크
-
embark_town: 탑승 항구 (영문)
-
alive: 생존여부 (영문)
-
alone: 혼자인지 여부
Dataset — "tips"
1 | tips = sns.load_dataset('tips') |
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 239 | 29.03 | 5.92 | Male | No | Sat | Dinner | 3 |
| 240 | 27.18 | 2.00 | Female | Yes | Sat | Dinner | 2 |
| 241 | 22.67 | 2.00 | Male | Yes | Sat | Dinner | 2 |
| 242 | 17.82 | 1.75 | Male | No | Sat | Dinner | 2 |
| 243 | 18.78 | 3.00 | Female | No | Thur | Dinner | 2 |
244 rows × 7 columns
-
total_bill: 총 합계 요금표
-
tip: 팁
-
sex: 성별
-
smoker: 흡연자 여부
-
day: 요일
-
time: 식사 시간
-
size: 식사 인원
1 | # 배경 설정 |
1. countplot
항목별 갯수를 세어주는 countplot
- 해당 column을 구성하고 있는 value들을 자동으로 구분하여 보여준다
reference: <sns.countplot> Document
sns.countplot ( x=None, y=None, hue=None, data=None, color=None, palette=None )
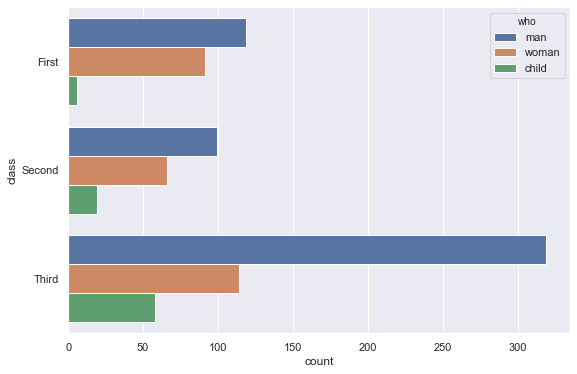
1-1. 세로로 그리기
1 | sns.countplot(x='class', hue='who', data=titanic) |
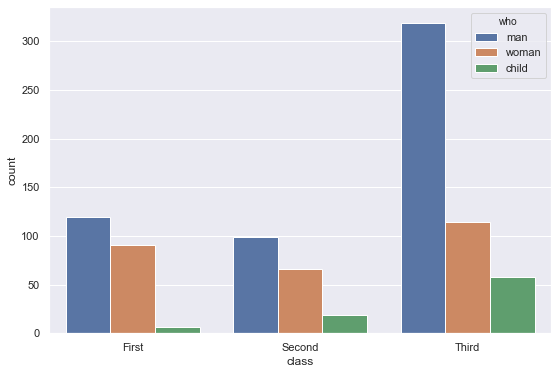
1-2. 가로로 그리기
1 | sns.countplot(y='class', hue='who', data=titanic) |
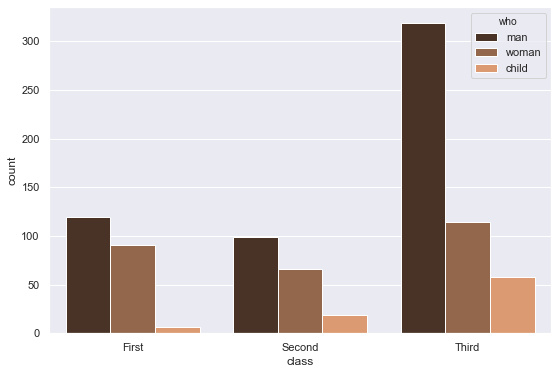
1-3. 색상 팔레트 설정
1 | sns.countplot(x='class', hue='who', palette='copper', data= titanic) |
2. distplot
matplotlib의 hist그래프와 kdeplot을 통합한 그래프다.
분포와 밀도를 확인할 수 있음
reference: <sns.distplot> Document
sns.displot ( a, hist=True, kde=True, rug=False, vertical=False, color=None )
- hist: histogram
- kde: kernel density estimate
- rug: rugplot
- vertical: If True, observed values are on y-axis
1 | # 샘플 데이터 생성 |
array([-3.39765920e-01, -1.48664049e+00, -5.57926444e-01, 3.25206560e-01,
-7.46665762e-01, -3.10926812e-01, -2.14536012e+00, 1.25905620e+00,
-2.07806423e-01, 5.56377038e-01, -2.20574498e+00, -1.15138577e-01,
-3.32417471e-01, 1.13927613e-01, -7.29559442e-01, -1.31243715e+00,
-8.27477111e-01, -1.24455099e+00, -5.44035731e-02, -1.85399773e+00,
-1.62571613e+00, 3.89312791e-01, 1.26815698e+00, -7.43355761e-01,
-1.34113997e+00, 2.67291801e-02, -4.74142344e-01, -1.07662894e+00,
-2.35607451e+00, 1.90337236e-01, -1.18577255e+00, -1.23238300e+00,
9.39298755e-01, -2.69078751e-01, -3.50418097e-01, 1.92109121e+00,
-1.46520490e-01, 3.90810577e-01, -6.60511307e-01, -1.46288431e+00,
1.26314685e+00, 2.38384651e-01, 8.03730080e-01, 2.83340226e-01,
-1.24219159e+00, -1.50458389e+00, -1.60213592e-01, 3.97086657e-01,
1.27321390e-01, -1.13722876e+00, -1.48448425e+00, 1.36136226e+00,
-2.34669327e-01, -1.32679409e+00, 1.59032718e+00, 7.53779845e-01,
-7.48815568e-01, 7.34822673e-03, 5.57358372e-01, 1.78429993e+00,
-1.50510591e+00, -3.87983571e-01, -7.57372493e-01, 6.25354827e-01,
1.44857563e-01, 7.78608476e-01, -6.61441801e-02, -1.24836018e+00,
1.77522984e+00, 1.60497019e-01, -1.18893624e+00, 1.93951152e+00,
-9.34504796e-01, 1.82000588e+00, -1.91594654e+00, -1.13118210e+00,
-4.13371342e-01, -5.07021131e-01, 1.57792370e+00, -2.52509848e+00,
1.86695906e-01, -1.18412859e+00, 1.49572473e-01, -3.53669860e-01,
1.38877682e+00, 2.53212949e-02, 7.79387552e-01, -7.41508306e-01,
4.10007279e-01, 1.96517288e-02, -5.69215198e-01, 1.45113980e+00,
-8.80722624e-01, 1.35468793e+00, -1.67677998e-03, -1.14952039e+00,
8.90718244e-01, -4.10411520e-01, 6.17620908e-01, 2.96993057e-01])
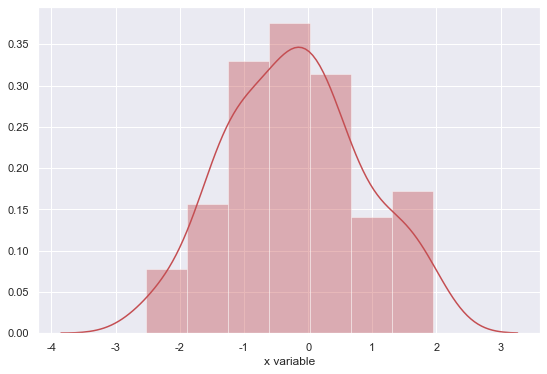
2-1. 기본 displot
1 | sns.distplot(x) # x: numpy array |
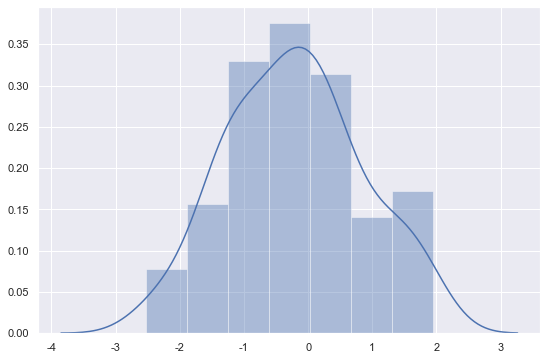
2-2. 데이터가 Series일 경우
1 | x = pd.Series(x, name='x variable') |
0 -0.339766
1 -1.486640
2 -0.557926
3 0.325207
4 -0.746666
...
95 -1.149520
96 0.890718
97 -0.410412
98 0.617621
99 0.296993
Name: x variable, Length: 100, dtype: float64
1 | sns.distplot(x) # x: Series |
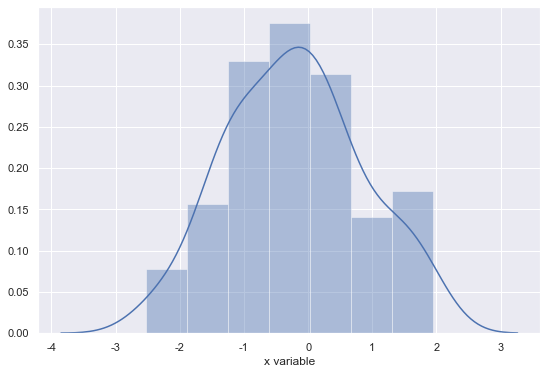
x가 Seires일 때는: 그래프에서 x label이 자동으로 Series 이름(column name) 으로 나타남
2-3. rugplot
데이터 위치를 x축 위에 작은 선분(rug)으로 나타내어 데이터들의 위치 및 분포를 보여준다
1 | sns.distplot(x, rug=True, hist=False, kde=True) |
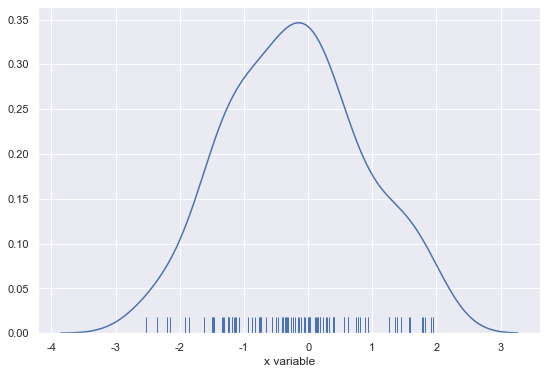
2-4. kde (kernel density)
kde 는 histogram보다 부드러운 형태의 분포 곡선을 보여주는 방법
1 | sns.distplot(x, rug=False, hist=False, kde=True) |
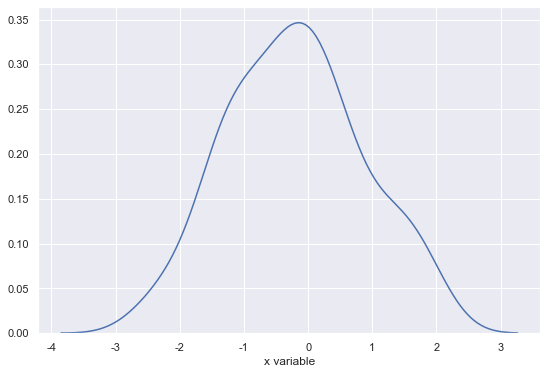
2-5. 가로로 표현하기
1 | sns.distplot(x, vertical=True) |
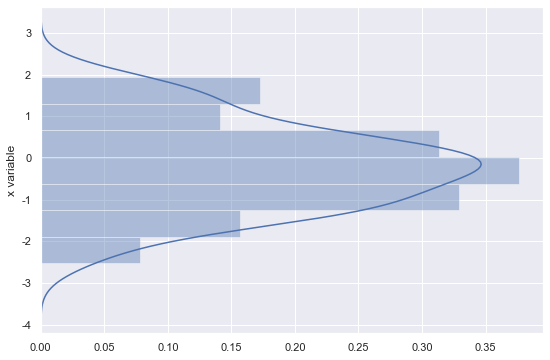
2-6. 컬러 바꾸기
1 | sns.distplot(x, color='r') |
3. heatmap
색상으로 표현할 수 있는 다양한 정보를 일정한 이미지위에 열분포 형태의 비쥬얼한 그래픽으로 출력하는 것이 특정이다
주로 활용되는 경우:
- pivot table의 데이터를 시각화할 때
- 데이터의 상관관계를 살펴볼 때
reference: <sns.heatmap> Document
sns.heatmap ( data, annot=None, cmap=None )
- annot: If True, write the data value in each cell
3-1. 기본 heatmap
1 | uniform_data = np.random.rand(10, 12) |
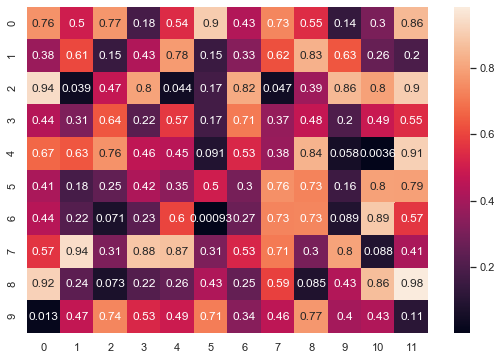
컬러가 진할수록 숫자가 0에 가깝고, 연할수록 1에 가깝다
3-2. pivot table을 활용하여 그리기
1 | tips |
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 239 | 29.03 | 5.92 | Male | No | Sat | Dinner | 3 |
| 240 | 27.18 | 2.00 | Female | Yes | Sat | Dinner | 2 |
| 241 | 22.67 | 2.00 | Male | Yes | Sat | Dinner | 2 |
| 242 | 17.82 | 1.75 | Male | No | Sat | Dinner | 2 |
| 243 | 18.78 | 3.00 | Female | No | Thur | Dinner | 2 |
244 rows × 7 columns
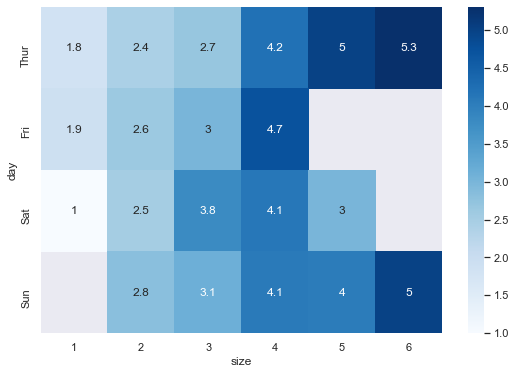
1 | pivot = tips.pivot_table(index='day', columns='size', values='tip') |
| size | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| day | ||||||
| Thur | 1.83 | 2.442500 | 2.692500 | 4.218000 | 5.000000 | 5.3 |
| Fri | 1.92 | 2.644375 | 3.000000 | 4.730000 | NaN | NaN |
| Sat | 1.00 | 2.517547 | 3.797778 | 4.123846 | 3.000000 | NaN |
| Sun | NaN | 2.816923 | 3.120667 | 4.087778 | 4.046667 | 5.0 |
1 | sns.heatmap(pivot, cmap='Blues', annot=True) |
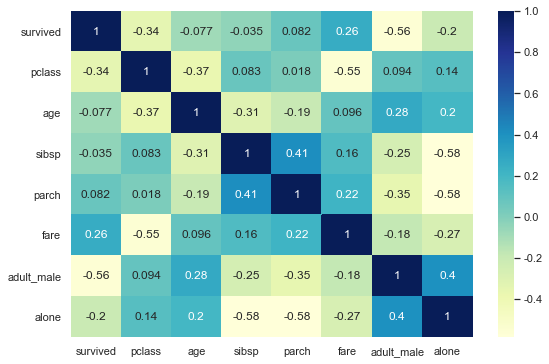
3-3. correlation(상관관계)를 시각화
corr() 함수는 데이터의 상관관계를 보여줌
1 | titanic.corr() |
| survived | pclass | age | sibsp | parch | fare | adult_male | alone | |
|---|---|---|---|---|---|---|---|---|
| survived | 1.000000 | -0.338481 | -0.077221 | -0.035322 | 0.081629 | 0.257307 | -0.557080 | -0.203367 |
| pclass | -0.338481 | 1.000000 | -0.369226 | 0.083081 | 0.018443 | -0.549500 | 0.094035 | 0.135207 |
| age | -0.077221 | -0.369226 | 1.000000 | -0.308247 | -0.189119 | 0.096067 | 0.280328 | 0.198270 |
| sibsp | -0.035322 | 0.083081 | -0.308247 | 1.000000 | 0.414838 | 0.159651 | -0.253586 | -0.584471 |
| parch | 0.081629 | 0.018443 | -0.189119 | 0.414838 | 1.000000 | 0.216225 | -0.349943 | -0.583398 |
| fare | 0.257307 | -0.549500 | 0.096067 | 0.159651 | 0.216225 | 1.000000 | -0.182024 | -0.271832 |
| adult_male | -0.557080 | 0.094035 | 0.280328 | -0.253586 | -0.349943 | -0.182024 | 1.000000 | 0.404744 |
| alone | -0.203367 | 0.135207 | 0.198270 | -0.584471 | -0.583398 | -0.271832 | 0.404744 | 1.000000 |
1 | sns.heatmap(titanic.corr(), annot=True, cmap='YlGnBu') |
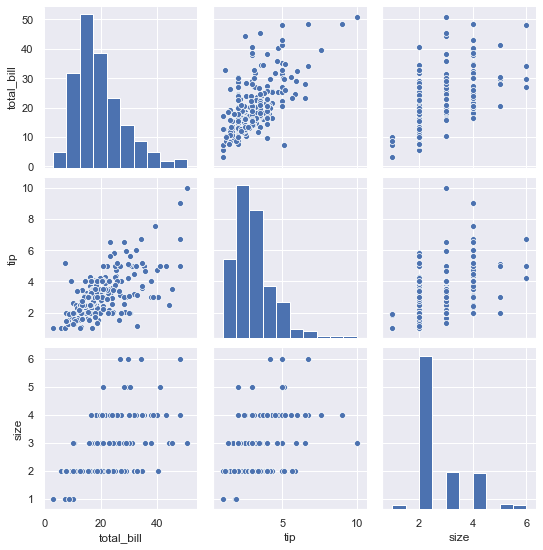
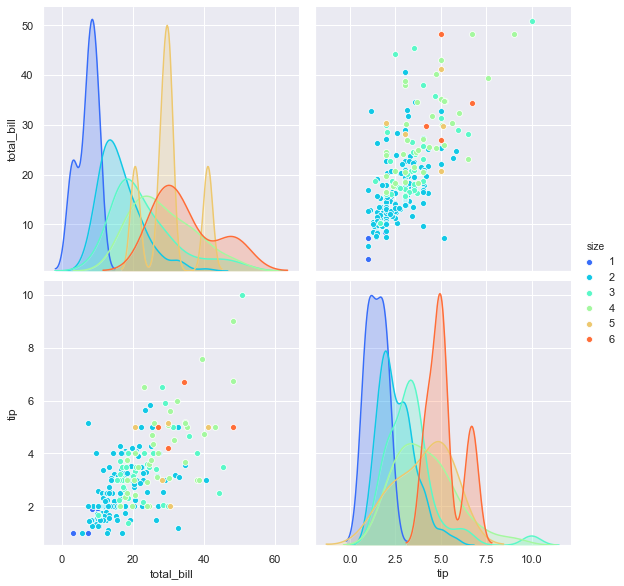
4. pairplot
pairplot은 grid 형태로 각 집합의 조합에 대해 히스토그램과 분포도를 그린다.
(숫자형 column에 대해서만 그려줌)
reference: <sns.pairplot> Document
sns.pairplot ( data, hue=None, palette=None, height=2.5 )
1 | tips.head() |
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
4-1. 기본 pairplot 그리기
1 | sns.pairplot(tips) |
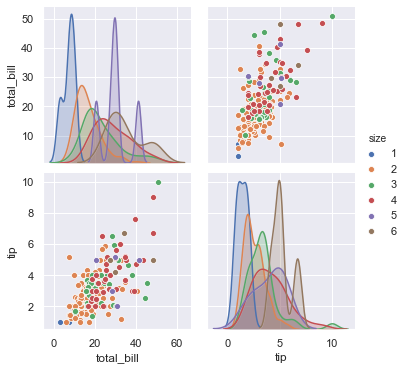
4-2. hue 옵션으로 특성 구분
1 | sns.pairplot(tips, hue='size') |
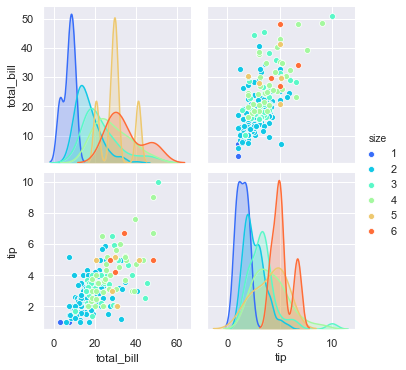
4-3. 컬러 팔레트 적용
1 | sns.pairplot(tips, hue='size', palette='rainbow') |
4-4. 사이즈 적용
1 | sns.pairplot(tips, hue='size', palette='rainbow', height=4) |
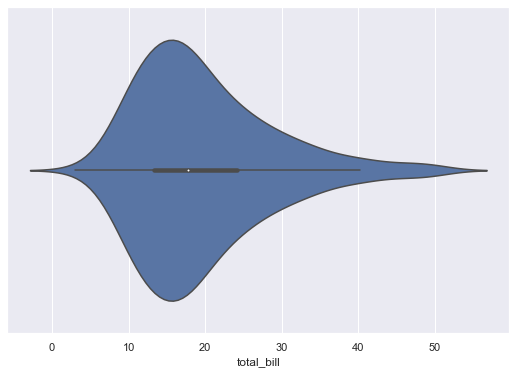
5. violinplot
마이올린처럼 생긴 violinplot다.
column에 대한 데이터의 비교 분포도를 확인할 수 있다.
- 곡선형 부분 (뚱뚱한 부분)은 데이터의 분포를 나타냄
- 양쪽 끝 뾰족한 부분은 데이터의 최소값과 최대값을 나타냄
reference: <sns.violinplot> Document
sns.violinplot ( x=None. y=None, hue=None, data=None, split=False )
- split: When using hue nesting with a variable that takes two levels, setting split to True will draw half of a violin for each level. This can make it easier to directly compare the distributions.
1 | tips.head() |
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
5-1. 기본 violinplot 그리기
1 | sns.violinplot(x=tips['total_bill']) |
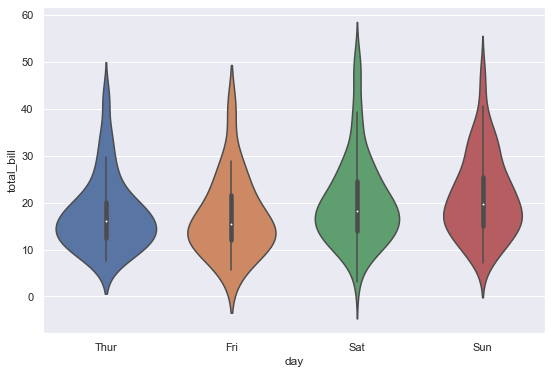
5-2. 비교 분포 확인
x, y축을 지정해줌으로써 바이올린을 분할하여 비교 분포를 볼 수 있다
1 | sns.violinplot(x='day', y='total_bill', data=tips) |
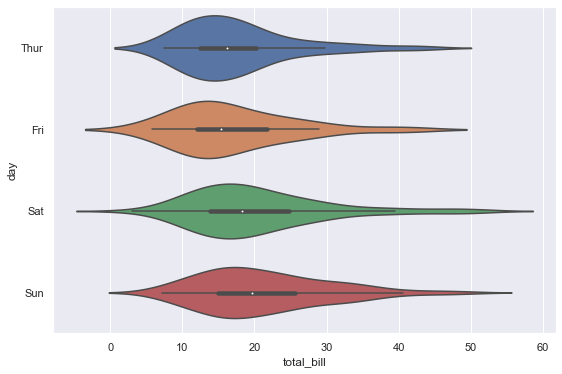
5-3. 가로로 뉘인 violinplot
- x축, y축 변경
1 | sns.violinplot(y='day', x='total_bill', data=tips) |
5-4. hue 옵션으로 분포 비교
사실 hue옵션을 사용하지 않으면 바이올린이 대칭이기 때문에 분포의 큰 의미는 없다.
하지만, hue옵션을 주면, 단일 column에 대한 바이올린 모양의 비교를 할 수 있다.
1 | sns.violinplot(x='day', y='total_bill', hue='smoker', data=tips, palette='muted') |
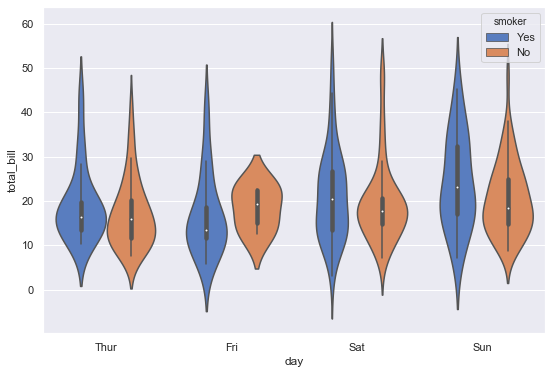
split 옵션으로 바이올린을 합쳐서 볼 수 있다
1 | sns.violinplot(x='day', y='total_bill', hue='smoker', data=tips, palette='muted', split=True) |
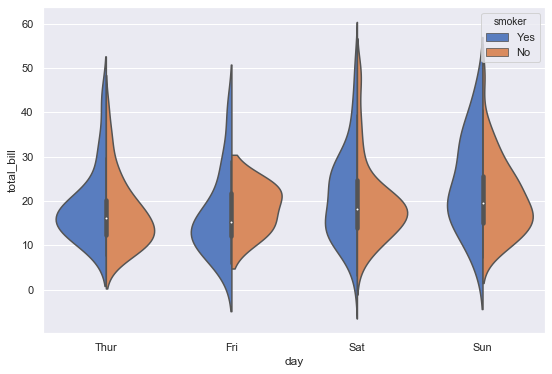
violinplot은 이런 경우에 많이 활용된다
6. lmplot
lmport (initial: 소문자 L) 은 column간의 선형관계를 확인하기에 용이한 차트임.
또한, outlier도 같이 짐작해 볼 수 있다.
reference: <sns.lmplot> Document
sns.lmplot ( x, y, data, hue=None, col=None, col_wrap=None, row=None, height=5 )
1 | tips.head() |
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
6-1. 기본 lmplot
1 | sns.lmplot(x='total_bill', y='tip', data=tips, height=6) |
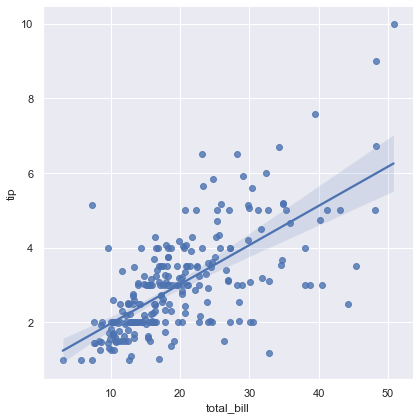
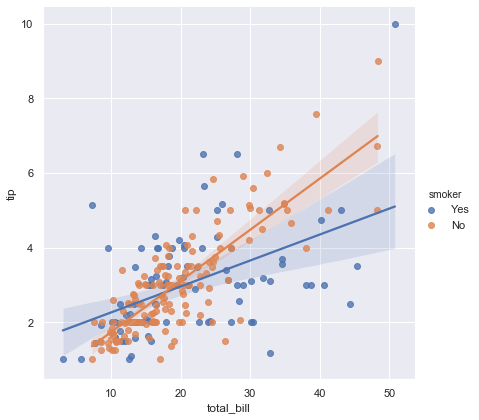
6-2. hue 옵션으로 다중 선형관계 그리기
아래의 그래프를 통하여 비흡연자가, 흡연자 대비 좀 더 가파른 선형관계를 가지는 것을 볼 수 있다
1 | sns.lmplot(x='total_bill', y='tip', hue='smoker', data=tips, height=6) |
6-3. col 옵션을 추가하여 그래프를 별도로 그려볼 수 있다
또한, col_wrap으로 한 줄에 표기할 column의 갯수를 명시할 수 있다
1 | sns.lmplot(x='total_bill', y='tip', hue='smoker', col='day', col_wrap=2, data=tips, height=6) |
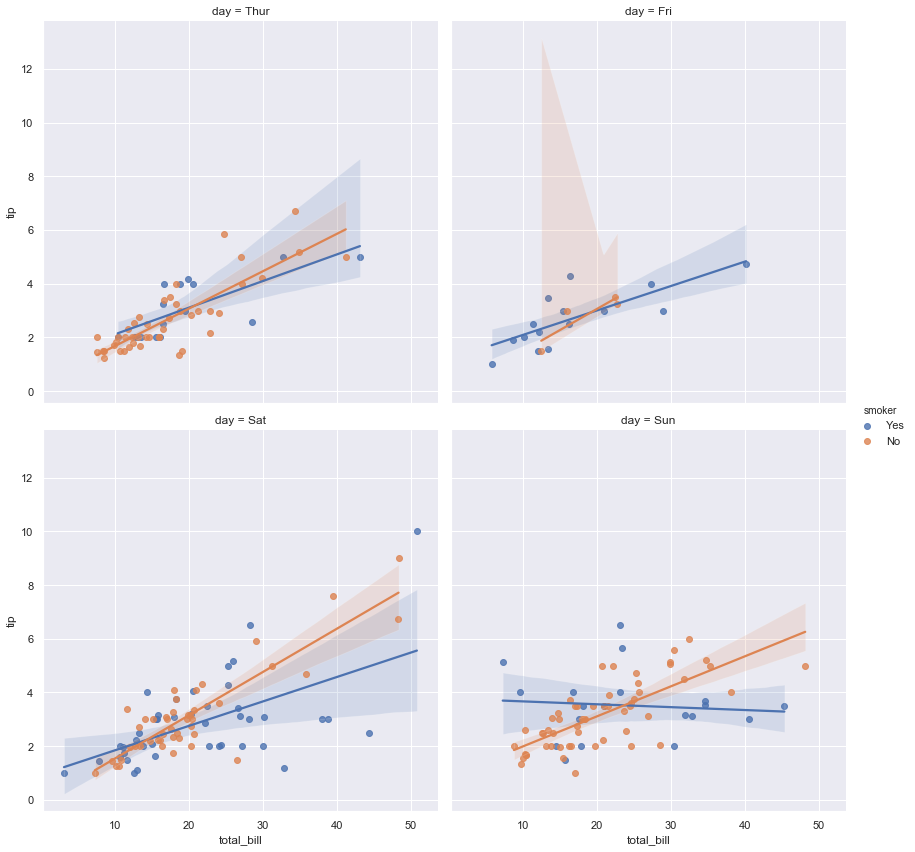
7. relplot
두 column간 상관관계를 보지만 lmport처럼 선형관계를 따로 그려주지 않다
reference: <sns.replot> Document
sns.relplot ( x, y, data, hue=None, col=None, row=None, height=5, palette=None )
1 | tips.head() |
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
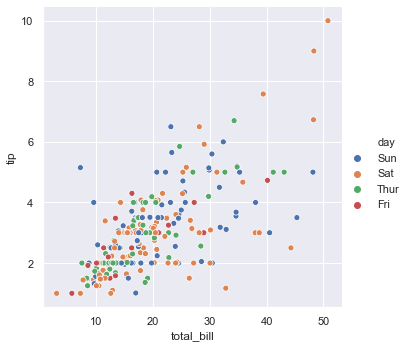
7-1. 기본 relplot
1 | sns.relplot(x='total_bill', y='tip', hue='day', data=tips) |
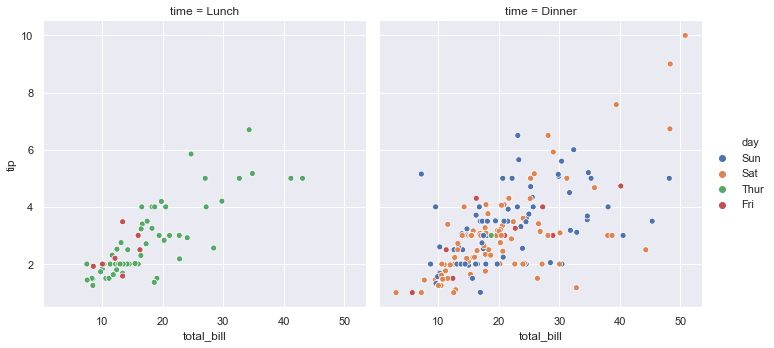
7-2. col 옵션으로 그래프 분할
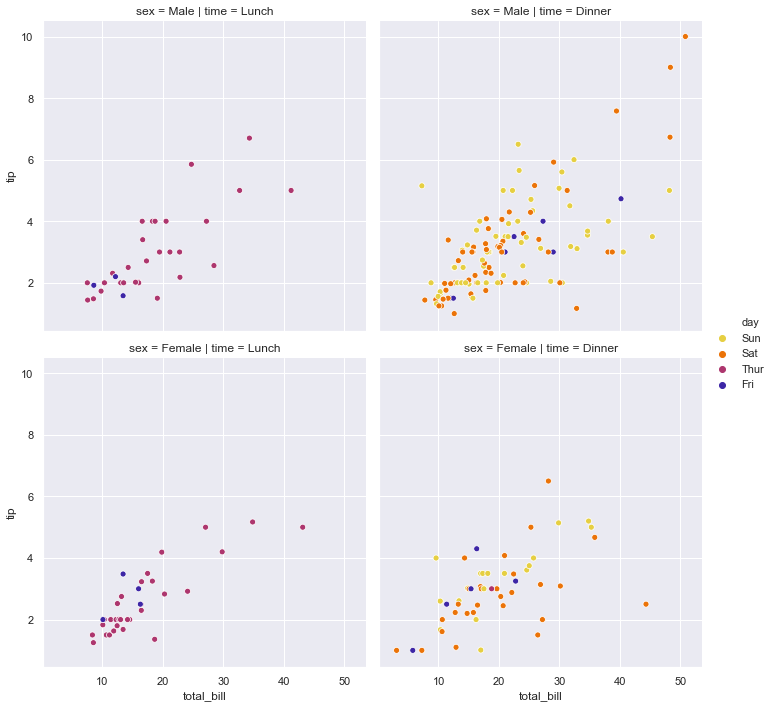
1 | sns.relplot(x='total_bill', y='tip', hue='day', col='time', data=tips) |
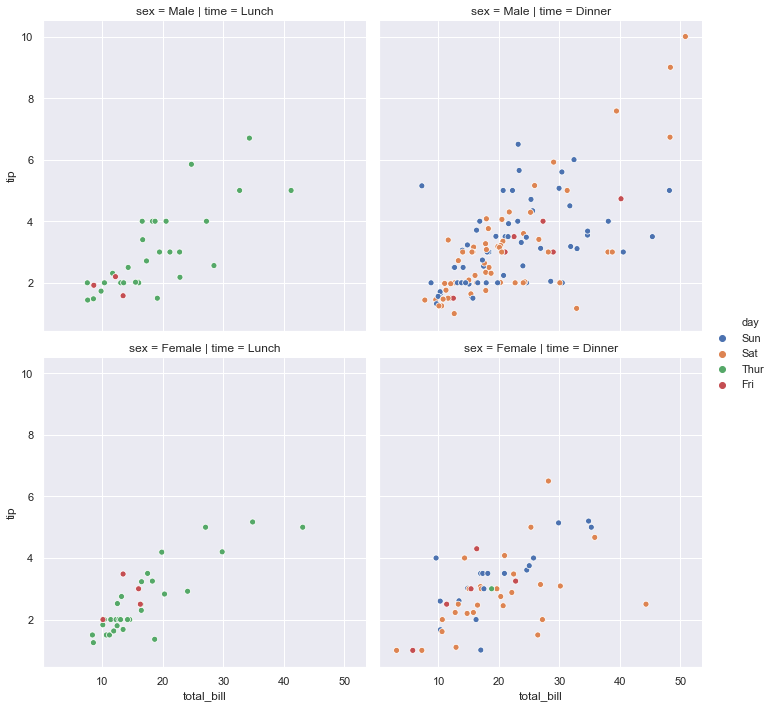
7-3. row와 column에 표기할 데이터 column 선택
1 | sns.relplot(x='total_bill', y='tip',hue='day', col='time', row='sex', data=tips) |
7-4. 컬러 팔레트 적용
1 | sns.relplot(x='total_bill', y='tip', hue='day', col='time', row='sex', data=tips, palette='CMRmap_r') |
8. jointplot
jointplot은 scatter(산점도)와 histogram(분포)을 동시에 그려줌.(숫자형 데이터만)
reference: <sns.jointplot> Document
sns.jointplot ( x, y, data=None, kind=‘scatter’, height=6 )
- kind: kind of plot to draw. {‘scatter’, ‘reg’, ‘resid’, ‘kde’, ‘hex’}
1 | tips.head() |
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
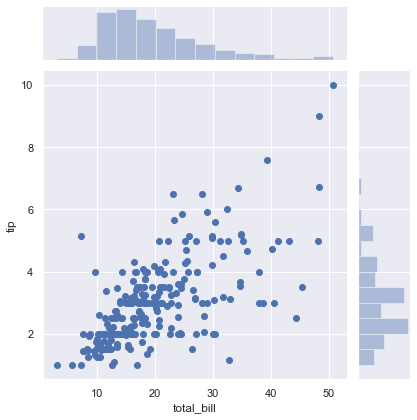
8-1. 기본 jointplot 그리기
default 로 "scatter plot"을 그린다 (kind=‘scatter’)
1 | sns.jointplot(x='total_bill', y='tip', data=tips) |
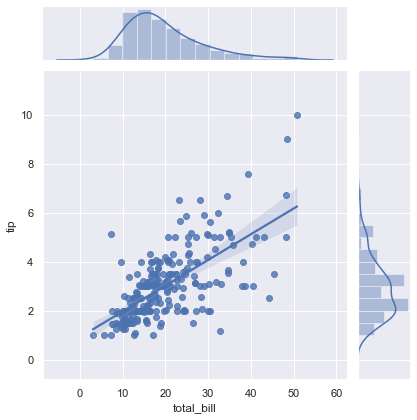
8-2. 선형관계를 표현하는 regression 라인 그리기
옵션: kind='reg’
1 | sns.jointplot('total_bill', 'tip', data=tips, kind='reg') |
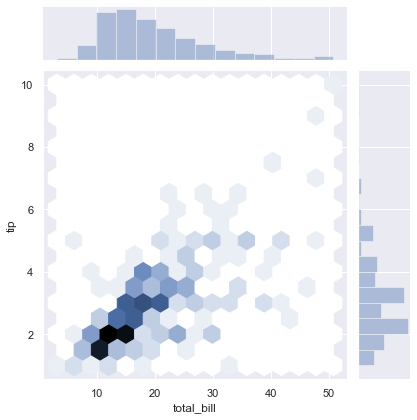
8-3. hex 밀도 보기
옵션: kind='hex’
1 | sns.jointplot('total_bill', 'tip', data=tips, kind='hex') |
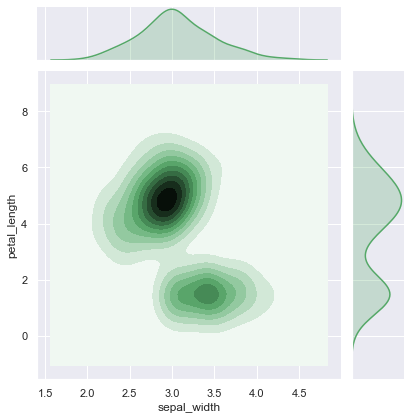
8-4. 등고선 모양으로 밀집도 확인하기
kind=‘kde’ 옵션으로 데이터의 밀집도를 보다 부드러운 선으로 확인할 수 있다
1 | iris = sns.load_dataset('iris') |
| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
| ... | ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 | virginica |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 | virginica |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | virginica |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | virginica |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | virginica |
150 rows × 5 columns
1 | sns.jointplot('sepal_width', 'petal_length', data=iris, kind='kde', color='g') |