텍스트 마이닝 (Text Mining) 소개
1. 텍스트 마이닝의 개념
텍스트 마이닝은 비정형 및 반정형 텍스트 데이터에 대하여 자연어 처리(Natural Langrage Precessing) 기술과 문서 처리 기술을 적용하여 가치와 의미가 있는 정보를 찾아내는(Mining) 기술입니다.
2. 텍스트 마이닝 응용분야
단어의 빈도수 기반
- Word Cloud: 텍스트 데이터에서의 단어 등장 빈도수 시각화
- 문서 분류: 감성 분류
- Topic Modeling: 텍스트 데이터를 분석하여 여러 Topic으로 Clustering 하는 작업
단어의 의미 기반
-
Semantic Analysis: 사람처럼 자연어를 이해하기
3. 텍스트 데이터의 처리 방법
3-1. BoW (Bag of Words)
단어 가방(Bag of Words) 모델은 문장의 문법 및 단어 순서를 무시하고 텍스트 문서를 "단어"로 변환한 후 다양한 측정 값을 계산할 수 있도록 "가방"형식으로 저장해놓는 겁니다.
단어 가방 모델에서 계산 된 가장 일반적인 유형의 특성 또는 기능은 용어 빈도, 즉 용어가 텍스트에 나타나는 횟수입니다.
《기생충》중의 한 대사로 예를 들어 볼게요.

이 문장에서 “그”, “을”, "듯"과 같이 실질적인 의미가 없는 "불용어"를 제외하고 의미 있는 “형태소” 단어와 해당 형태소의 등장 횟수을 추출합니다.
그럼 다음과 같은 표로 요약할 수 있겠습니다.
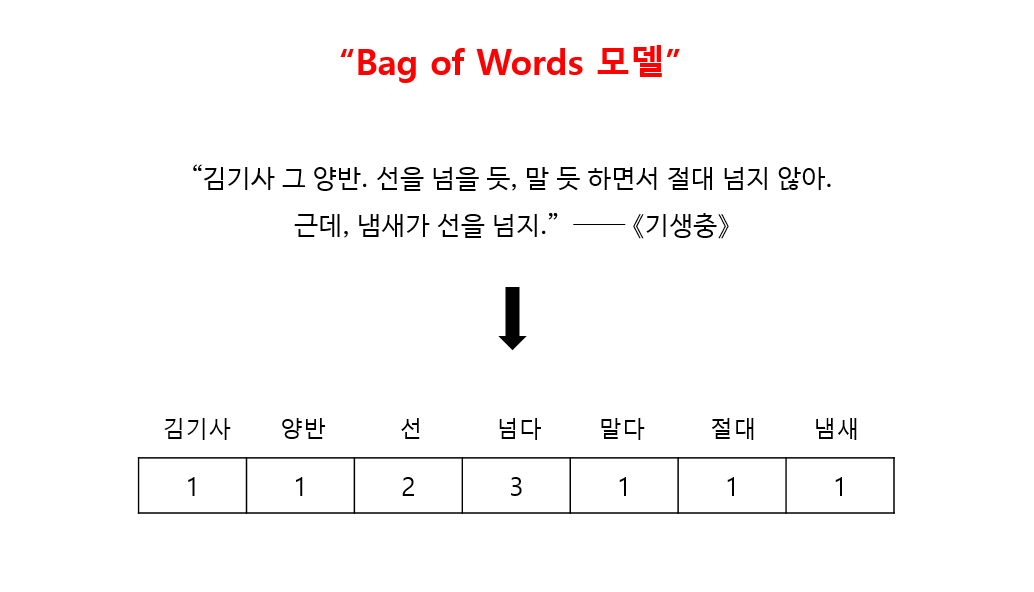
이것이 바로 "Bag of Words 모델"입니다.
3-2. 문서 단어 행렬 (Document-Term Matrix, DTM)
위에 설명드린 Bag of Words는 한 문장에 대해 적용하는 것이고, 문장이 여러 개가 있을 때는 (DataFrame 형태) 문서 단어 행렬 (Document-Term Matrix) 로 표현됩니다.
똑같이 《기생충》중의 대사들로 예를 들어 볼게요.

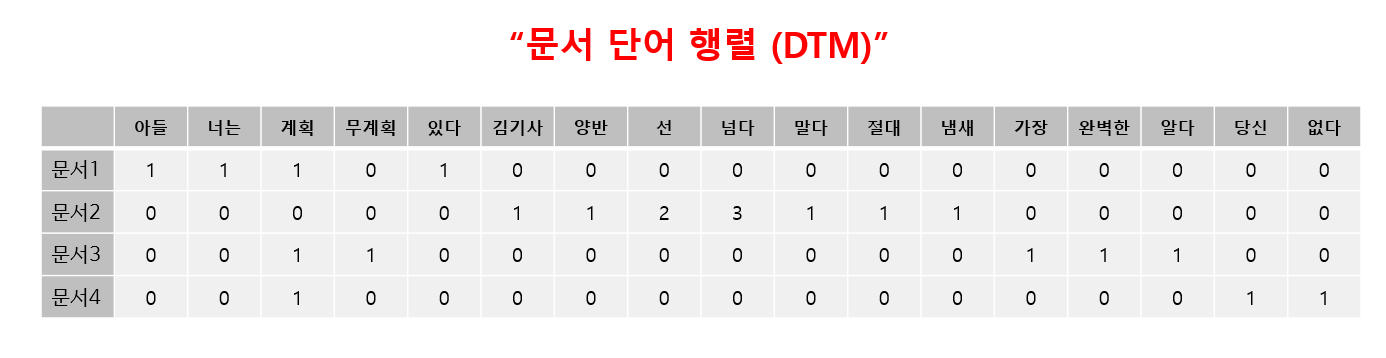
이처럼 여러 문장의 경우에 "문서 단어 행렬"은 위와 같이 표현 됩니다.
3-3. 단어의 중요도를 계산하는 방법 (TF-IDF)
문서 단어 행렬은 그저 단어의 등장 횟수를 단순히 세는 겁니다. 각 문장에서 어떤 단어가 중요한지 알 수 없습니다.
이를 알아내기 위해 우리는 “TF-IDF (Term Frequency-Inverse Document Frequency)” 라는 지표를 사용합니다.
-
TF (Term Frequency): 특정 문서에서 특정 단어의 등장 횟수
-
DF (Document Frequency): 특정 단어가 등장한 문서의 수
-
IDF (Inverse Document Frequency): DF와 반비례 값을 가지는 수식
-
TF-IDF (Term Frequency-Inverse Document Frequency): TF와 IDF를 곱한 값
TF-IDF로 특정 문서 안의 특정 단어의 중요도를 나타나는 원리는:
특정 문서에서는 많이 등장했으면서 다른 문서에서 잘 등장하지 않은 단어가 결국 이 문서에서 가장 중요한 단어가 될것이다라는 가설입니다.
[예] 문서1에서 "아들"과 “계획” 이 두 단어의 TF-IDF를 한번 계산해봅시다.
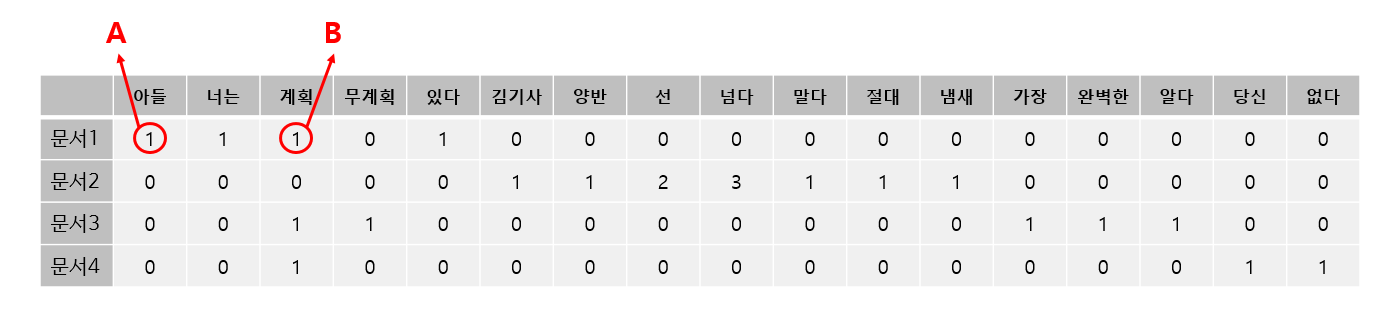
- Step 1. TF
A: 1
B: 1 - Step 2. DF
A: 1
B: 3 - Step 3. IDF
A:
B: - Step 4. TF-IDF
A: 1 * 0.6931 = 0.6931
B: 1 * 0 = 0
혜석:
"계획"이라는 단어가 《기생충》의 문장들에서 너무 많이 등장해서 문서1에서 특별히 중요한 단어라고 볼 수 없다.
하지만 "아들"이라는 단어가 다른 문장에서 한번도 나타나지 않았기 때문에 문장1에서는 매우 중요하다고 볼 수 있다


